Original URL: https://www.theregister.com/2009/10/19/cmu_fawn_clusters/
Boffins fawn over dirt cheap server clusters
Fast array of wimpy nodes
Posted in Channel, 19th October 2009 05:18 GMT
A team of researchers at Carnegie Mellon University have been studying how they can make cheap, low-powered, and relatively unimpressive server nodes gang up and do more work than the two-socket x64 server that is the workhorse of the IT industry. They have come up with an approach called FAWN, which is short for Fast Array of Wimpy Nodes.
Last week at the ACM's Symposium on Operating Systems Principles, Carnegie Mellon researchers working with Intel Labs presented a paper (pdf) on the FAWN concept, demonstrating where a combination of wimpy server nodes built on motherboards that usually end up in inexpensive PCs or homegrown media servers can do more of the Web 2.0-style query work per unit of energy than more powerful boxes.
This is actually the second paper that the FAWN project has put out this year; the first one (pdf), introducing the work done by David Andersen, Jason Franklin, Amar Phanishayee, Lawrence Tan, and Vijay Vasudevan of Carnegie Mellon and Michael Kaminsky of Intel Labs.
This is by no means the first time that researchers, hyperscale data centers and IT suppliers have taken a look at clustering low-powered and relatively wimpy server nodes together to aggregate large amounts of computing, memory, and I/O capacity together. But the FAWN project researchers are trying to push the envelope - the power envelope, that is - and push it down as low as it can practically go.
To demonstrate what an array of FAWN machines can do, The Carnegie Mellon researchers say they have created a key value storage cluster that is similar in concept to Amazon's Dynamo and the open source projects Memcached (which is championed these days by Facebook, among others) and Voldemort (a distributed key value storage system, which is a database but not a relational or object database and which is used by LinkedIn). The prototype FAWN machines - the project is in its third generation - are the kinds of things you could build in your living room on a fairly modest budget.
The first generation wimpy nodes consisted of a cluster of eight baby PCs in beige boxes networked with a cheap switch, and the second generation mounted 14 boards together on a bare frame and didn't even bother with a chassis. The picture shown is of the second generation FAWN setup, but according to the paper published at SOSP, the latest cluster has 21 nodes, each using a 500 MHz Atom processor, 256 MB of main memory, and 4 GB of CompactFlash storage.
This is not, by any stretch of the imagination, a powerful PC. In fact, this is wimpy even for a wimpy PC. But according to the CMU researchers, here is the key thing that has Google Network Appliance kicking in money for the FAWN project alongside Intel: Each one of those wimpy nodes consumers under 5 watts of juice as it is running at near peak performance processing queries and retrieving data from the FAWN distributed store (FAWN-DS).
A node can do 1,300 256-byte queries per second, according to the paper and process 364 queries per joule of energy. This, say the techies, is two orders of magnitude better bang per joule than a regular server can deliver.

The second-generation FAWN Project cluster
One of the key factors behind the wimpy nodes doing so well is that on such a node, processing, main memory and flash memory speeds are more in synch than they are on a modern x64 or RISC server. Because CPUs are revving so much faster than the I/O devices that feed them, they are often tapping their feet, waiting for data.
To compensate for this, modern CPUs have layered on all kinds of features - speculative execution, out-of-order execution, superscalar execution, simultaneous multithreading, branch prediction and the like as well as two or three layers of cache - that try to make up for the big gap between CPUs and their I/O. The problem is, these features not only cost money, they also consume a lot of power. So you get the CPUs to do the work, but at a big cost.
Without naming any names, the Carnegie Mellon researchers say that a quad-core superscalar processor running at several gigahertz can process approximately 100 million instructions per joule, but these in-order, relatively stupid chips used in the wimpy nodes can deliver one billion instructions per joule while running at a much lower frequency.
To make some comparisons, the researchers took a single server node based on an Intel desktop quad-core Q6700 processor and put 2 GB of memory on it as well as a Mtron Mobi solid state disk. This machine was set up to run Linux with a tickless kernel (2.6.27) and all of the power management features were optimized. The machine consumed 64 watts when idle, and from 83 watts to 90 watts when it was loaded up doing query work.
The Intel server node was able to process 4.771 random 256 byte reads, providing an efficiency rating of 52 queries per joule. The 21-node FAWN cluster idled at 83 watts, and peaked at 99 watts during puts and 91 watts during gets. This is 36,000 queries against a 20 GB dataset, which is what gives you the 364 queries per joule (including the power drawn from the switch linking the nodes). Nodes based on the desktop mobo that Carnegie Mellon tested using disk drives instead of SSD did awful, as you would expect, delivering only 17 queries per joule.
The techies at Carnegie Mellon and Intel are not nuts. They are not suggesting that there is no place for disk, but rather that you have to have the technology reflect the dataset size and query rate you are trying to deliver, and you have to make choices.
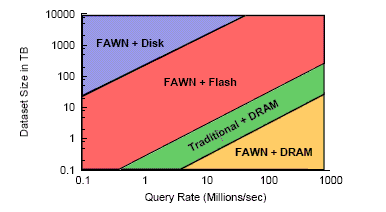
The tradeoffs between queries and data set size
As their research shows, there is a trade-off that seems to be unavoidable for now, because disk drives are more capacious than flash drives, which are fatter than main memory. And that is this: If you want to query large data sets, you need to use disks and that means you can't hit the high query rates of a FAWN array using only main memory (possible if you datasets are really tiny) or flash. That means you will pay a lot more for servers, and they will be a lot less efficient. ®