This article is more than 1 year old
Nvidia stretches CUDA coding to ARM chips
OpenACC is building up momentum as Chipzilla ignores it
ISC 2013 Nvidia's new CUDA 5.5 release aims to overcome the inherent mathematical suckiness of the ARM architecture by unleashing the powers of GPUs working in conjunction with those popular low-power chips – and not just ones from Nvidia.
Nvidia is working on its own implementation of a 64-bit ARM processor, code-named Project Denver, and is keen on porting its CUDA parallel programming environment to it. But if Nvidia wants to sell a lot of Tesla coprocessor cards to do the number crunching for modestly powered ARM chips, it needs to make CUDA available not just on its own future ARM processors, but on any and all ARM-based server chips.
And that is precisely what Nvidia is doing with its CUDA 5.5 tool, which was announced at the International Super Computing conference in Leipzig, Germany.
"We can't just support an Nvidia ARM platform," explains Sumit Gupta, general manager of the Tesla Accelerated Computing business unit at the company. "There are ARM CPUs coming into the enterprise market, and by next year there will be a whole bunch of them, and we want to connect GPUs to all of them. This will open up CUDA to more customers."
And help Nvidia sell more Tesla coprocessors. Perhaps a lot more.
There are many, many more ARM chips sold every year than x86 processors, if you count all of the chips sold into smartphones, tablets, and other devices, and Nvidia wants to tap its programming environment into those chips. The reason is simple: generally speaking, ARM chips suck at math relative to x86 floating-point units – and certainly compared to GPUs.
"The ARM CPUs coming to market either do not have floating-point math or have very low-performing floating point units," says Gupta. "We think GPU accelerators are going to be, in effect, the floating-point units for ARM processors."
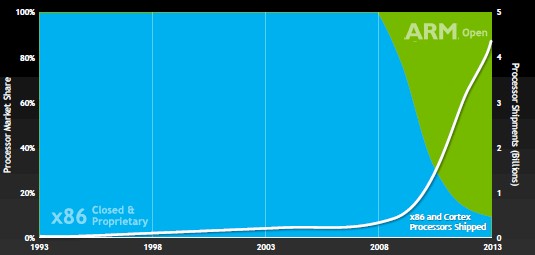
The number of ARM chips shipped dwarfs the number of x86 chips
That is certainly the case with the future "Logan" and "Parker" generations of Tegra processors, which will marry ARM chips with current-generation "Kepler" GPUs and future "Maxwell" GPUs. (The latter gets the full-on 64-bit Denver cores.) But, Gupta says, Nvidia is very keen on any ARM processor being able to shift work to a GPU coprocessor, and hence CUDA 5.5's support for any ARM server chip.
With CUDA 5.5, the parallel programming environment has native compilation on 32-bit and 64-bit ARM processors, just like it has native compilation for x86 processors from Intel or AMD. The compilers that plug into CUDA are optimized to make a few serial tasks run well on x86 chips, which tend to rev high as well as burn a lot of juice. The GPU coprocessor, on the other hand, is optimized to run many tasks in parallel, and with the latest "Kepler" GPUs, it can take advantage of dynamic parallelism and Hyper-Q, features that radically improve the throughput of a GPU as it crunches numbers.
Gupta says that the 5.5 update of CUDA, the Hyper-Q feature, which allows for up to 32 different MPI processes to be launched on a high-end Tesla K20 or K20X, is now being supported on a wider range of Linux operating systems. Interestingly, the tool also has a fast cross-compiler that allows for developers to compile ARM applications on an x86 processor and then move the compiled code over to an actual ARM chip to execute it.
The new CUDA also has a guided performance analysis tool, which helps developers figure out where there are bottlenecks in their code. This will be particularly important as developers accustomed to coding for x86 processors encounter their first ARM chips.
The CUDA 5.5 environment makes ARM a first-class citizen next to Xeon and Opteron processors. It lets the CUDA compiler, debugger, and performance analysis tools (Visual Profiler and Nsight Eclipse Edition) as well as GPU-accelerated math libraries for fast Fourier transforms, random number generators, sparse matrix operations, and various algorithms commonly used in signal and image processing, work on ARM chips as they do on x86 processors today.
Nvidia is chucking in documentation and code snippets to give ARM programmers a head start. You can download the latest CUDA here for free if you want to play. CUDA 5.5 supports a wider array of Linuxes on ARM chips, by the way, than did a pre-release version.
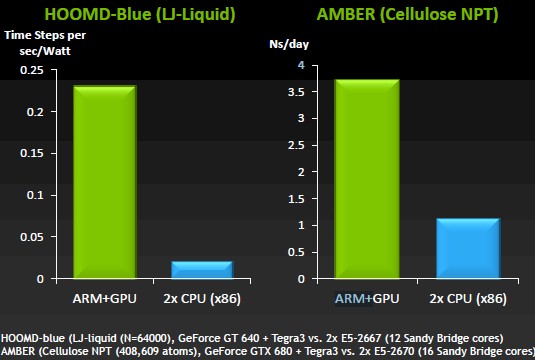
Nvidia says the combination of ARM CPUs and Tesla GPUs will best x86 processors
Nvidia is also talking up the kind of speed that customers can expect to see with the double-whammy of an ARM CPU and a CUDA-enabled discrete GPU and, more importantly for the Nvidia marketing machine, the energy savings that comes from the ceepie-geepie combo.
The kind of speedups as shown in the simulations above are what Gupta says are typical compared to current Xeon processors from Intel. HOOMD-Blue is a molecular dynamics application that in this case is simulating a liquid, and the combination of a four-core Tegra 3 chip plus a GeForce GT640 GPU card is considerably more energy-efficient than a dual-socket Xeon E5-2667 with a total of twelve cores. And AMBER, which is a computational chemistry app, is seeing around a factor of 3.5 speedup moving to a dinky ARM plus a modest GPU when compared to a two-socket Xeon E5 box. In this case, it is a Tegra 3 married to a GeForce GTX680 graphics card compared to a Xeon E5-2670 with sixteen cores.
CUDA, of course, is a parallel programming environment that only works in conjunction with Nvidia GPUs, but Nvidia has been a force behind OpenACC, which is an effort by the GPU maker, some compiler devs, and big academic and government research labs to set a standard for parallel programming for CPUs and GPUs.
Thus far, Intel has demurred from joining that effort, but this week at ISC, Nvidia said that there are twice as many organizations behind it than before, with Tokyo Institute of Technology, Edinburgh Parallel Computing Centre, and Indiana University being the big new members joining Nvidia, Cray, Portland Group, Allinea, and others.
There are now 15 organizations behind OpenACC, and the application stack that has been ported to work with OpenACC has grown from six last year to 26 as of this week. So far, 40 software development firms have committed to creating accelerated versions of their applications using OpenACC; fourteen have yet to get the job done, but they are working on it.
The OpenACC 2.0 spec was ratified by the consortium members at ISC this week, and has tweaks to boost application performance and make the code more portable through the addition of more APIs. The updated OpenACC toolkit has tweaks to control the movement of unstructured data and add support for non-contiguous memory, among other things, that gooses the performance.
Gupta says that it can take a couple of weeks to port a modest application to run on a GPU – but you have to know what you are doing.
Over 1,000 programmers using OpenACC were surveyed, and 75 per cent said they were able to get a significant speedup on their code when used in conjunction with accelerators; 70 per cent said they had a "positive experience" with the effort. Just under two-thirds of those polled said they had a factor of 2X or more improvement in application performance using OpenACC, while just over a third said they got less than a 2X speedup.
Of course, the speedup depends on the accelerator you are using and the nature of your code. You are going to get a lot further with a Tesla K20 or K20X because of features such as dynamic parallelism and Hyper-Q, which are not available in the Tesla K10 or prior Fermi GPU coprocessors.
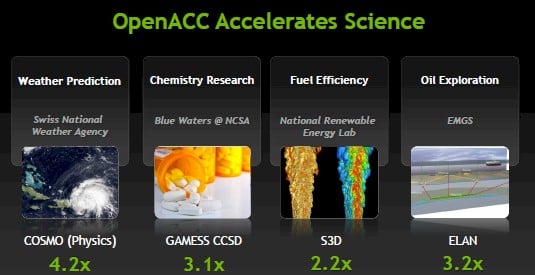
Early work on porting apps to GPU accelerators using OpenACC shows sims run quite a bit faster
"If people know explicit parallel programming, then CUDA is actually easy to pick up," says Gupta. "If you are a traditional sequential programmer, you need something like OpenACC. And OpenACC is a much easier on-ramp to the GPU than anything else out there."
It would be good, then, if OpenACC was also an easy on-ramp to Intel's Xeon Phi x86 coprocessors, but thus far – as you might have expected – Chipzilla has shown no interest in joining the party.
But if enough applications support the OpenACC framework, that could change. ®
