This article is more than 1 year old
Newbies Komprise hope to krush data sprawl
By reinventing ILM, HSM and file data management
Analysis Komprise is a data management startup saying it will save enterprises money by identifying and analysing file/unstructured data sprawl then shift it to cheap on-premises or in-cloud storage. This is a message put out by others, such as Catalogic and Primary Data. It overlaps with the copy data managers, such as Actifio, and the secondary data convergers such as Cohesity.
Others include Formation Data Systems and Hedvig. All share a common theme that secondary and unstructured data storage is overwhelming enterprise data centre infrastructures and significant savings can be achieved by shunting rarely accessed files stored on fast disk arrays off to cheaper and slower disk storage, such as an object store, or the public cloud.
What's Komprise got that's special?
We first wrote about it in June 2015, when it picked up $6m in A-round funding. At the time Komprise said it could reduce the management and cost burden of buying and operating existing storage by up to 70 per cent.
It started beta testing in November 2015 and headed to the market in July 2016. There were around 50 customers coming out of beta at the launch – including Electronic Arts, Cox Media Group, Agilent Technologies, Pacific Biosciences and Cadence – with a pretty horizontal spread across file-heavy markets such as genomics, biotech, financial services, engineering, oil and gas and the public sector.
Komprise also gained a $12m B-round earlier this year, taking total funding to $18m. Sun ZFS co-founder Bill Moore is an investor.
We sat down with COO and co-founder Krishna Subramanian at Dell EMC World to find out more about how the company's technology works.

Komprise COO Krishna Subramanian
Observers
There are three pieces of software: Observers, a Director and a Cloud Controller. The Observers run in virtual machines in a customer's data centre and are a scale-out resource – if you need another, just fire up another Observer VM.
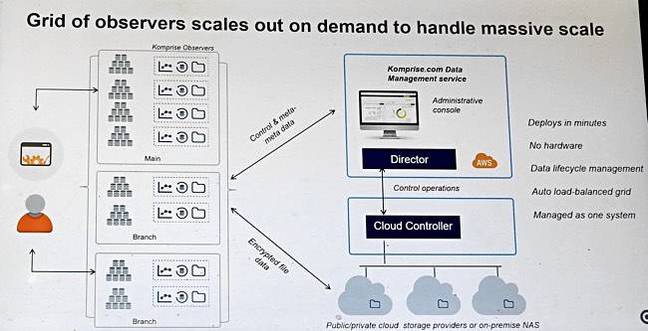
Komprise Observers
These are quasi-agents, hypervisor-agnostic, and load-balanced. They run outside of the data path, looking at filers – anything that exposes an NFS or SMB interface – on the customer's network and amassing metadata about the file estate (Komprise does not look at block data, or at HDS files – yet). This is cached in memory as a sparse computational cube* and forms a distributed data store** across the observers. Here we run into Komprise's patented and confidential technology.
The metadata includes how much data, file sizes, types and users, how fast the file estate is growing, and file access history so that the software can identify hot and cold data.
Subramanian said: "We work through open standards. There is no proprietary agent on the underlying silos and the Observers are non-invasive and non-intrusive, and our software is adaptive. We're the Nest thermostat of (file) data."
Director
The Observers send control and meta-metadata to the Director, and it is the Director that creates the storage admin UI and its data. It is an out-of-band entity and not an active data access controller.
The Director, by default, runs in the public cloud, being managed by Komprise, but can run in the customer's data centre. Subramanian insists that Komprise software never looks at a customer's file data content.
Although the Komprise file estate-generated metadata is held initially in memory across the Observers, it is persisted to disk in the customer's data centre as a Komprise data store. This persisted data store holds the condensed and coded representation of potentially billions of file metadata records generated by the Observers.
It is space efficient, with 100PB+ of customer file data needing only a few MBs of persisted data, and mostly stateless.
This representation can be used by the Observers, when they need to access it, to generate a picture of their section of the customer's file estate. When a new Observer is instantiated it goes to the Director to find out which part of the persistent data store it should use to generate its sparse computational cube.
Policies can be set to define various levels of file activity; such as very hot, hot, warm, cool, cold, etc. Data protection policies can also be set, relating to replication, active archiving (meaning disk rather than tape archiving) and tiering. The Komprise software GUI can show savings as policies are set, so that you can see the cost of different policies.
When a user confirms that files are to be moved, the original file access path, as far as accessing applications and users are concerned, does not change. A form of DNS lookup, with dynamic links, is used so that files can be correctly accessed after being migrated without the app/user-facing file directory information changing. A stub is not left behind when files are moved, as was the case with old file virtualisation technology.
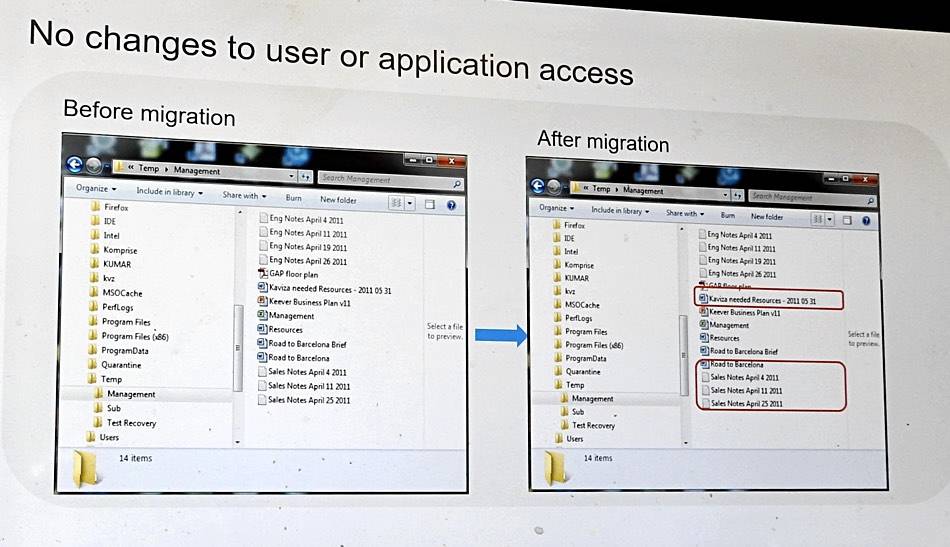
File directory info before and after migration showing unchanged info and with dynamic links. Click to enlarge
Partners and price
Subramanian says: "Our product is adaptive and learns and moves data intelligently. When we move data to the cloud we move it as an object. We are a file gateway to that data." The S3 protocol is used to send file objects to the cloud. Komprise also provides a degree of analytics to the file estate data it generates.
It partners with many file storage vendors: Dell EMC, HPE, IBM, NetApp, Quantum (Stornext, Lattus, Artico), SpectraLogic (Tape, Black Pearl, Verde) plus the three main public clouds, AWS, Azure and Google.
What's the product price? It's $150/TB of source data for a perpetual licence. That could be expensive, but Komprise argues it can provide a 70 per cent or so cost-saving.

Komprise cost-saving example
Competitive observations
Komprise's technology is a successor to earlier Hierarchical Storage Management (HSM) and Information Lifecycle Management (ILM) products, which, Subramanian says, "failed because they were intrusive, cumbersome, didn't scale, and were expensive".
In Komprise's view Primary Data runs in the data path, which is bad news, and doesn't scale. It has customers who have replaced Primary Data's software.
Catalogic, it says, looks at both structured and unstructured data, but is legacy and complicated in its approach.
Unlike Actifio, Komprise's software does not generate data copies, physical or virtual. And unlike cloud storage gateways such as Avere, Nasuni and Panzura, Komprise's gateway functionality is limited to moving cold data to (and back from) the cloud, not presenting it as a separate storage tier to file-accessing users and applications.
Subramanian said: "We preserve file semantics when we move data to the cloud."
Regarding Commvault, and only concerning archiving to the cloud, Subramanian says Komprise has a very low footprint in a customer's IT estate and saves a bundle more money, by tiering data to the cloud, than Commvault's software. In general Komprise does not compete with Commvault.
+Comment
It seems that $18m is not a lot of funding and the VC backers taking part in the B-round must have been impressed with the beta and software launch. Komprise now has to spread its wings and gain hundreds of customers for its software. That depends upon it proving its cost-saving effectiveness and being easy to adopt and use. ®
Bootnote
Why do all three of the companies founded by these three – Kovair, Kaviza and Komprise – start with K? That letter appears in all their own names: CEO Kumar Goswami, president and COO Krishna Subramanian, and CTO Mike Peercy.
* A sparse computational cube is a way of storing a dense representation of billions of small metadata records that takes up little space.
** This distributed data store is said by Subramanian to be what Google uses in its search facility.
