This article is more than 1 year old
Build-a-cluster students conjugate gradients for science and glory
Intrepid clusterers tackle a new(ish) benchmark
HPC Blog Student teams at SC16 were faced with a new(ish) benchmark during their 48-hour marathon run for the Student Cluster Competition Cup (there is no actual cup). The teams have always run the HPL (LINPACK) program, which is used to rank the TOP500 supercomputers in the world. But this year, they're also running the "book-end" HPCG (High Performance Conjugate Gradient) benchmark.
Both HPL and HPCG were developed by the same guy, Dr Jack Dongarra from the University of Tennessee, Knoxville.
Why a new benchmark?
HPL has been a pretty good tool for figuring out just how well our computers perform on highly numerically intensive workloads. It's time-tested for sure, but growing a little long in the tooth. When HPL was designed, the code looked a lot like what everyone was running on their supercomputers — a whole lot of linear algebra.
But today it's a different story. Current workloads are much more varied and stress different parts of the system. In fact, according to Dongarra, a computer designed for high LINPACK performance may actually lead to a system that's not so good for real-world applications today. He's hoping that HPCG will catch on and provide users with a better way to figure out how to design computers that are more closely matched to the workloads that they'll actually run.
HPCG is a much more complex benchmark. It contains tests that are representative of real-world scientific applications — like those with low computation to data access ratios, for example. It also tests how well a system copes with irregular memory access operations, which is something that HPL can't test at all. The benchmark rewards systems that optimize MPI collective operations like all-reduce, for example. For a much more detailed explanation of the benchmark, click here (PDF).
As Dr Dongarra once explained to me (over breakfast in Wuhan, to be more exact), HPL and HPCG can be seen as book ends. HPL shows you the best system performance you can expect from your gear, while HPCG displays what is probably the worst performance you will get. The truth for your real-world applications is probably somewhere in the middle.
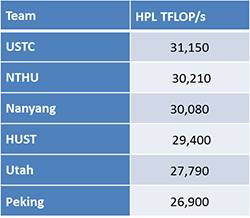
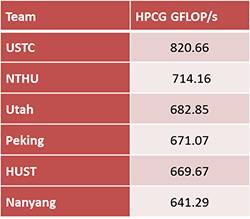
We see exactly that effect from the competitors in the SC16 Student Cluster Competition. I've inserted tables for both HPL (blue) and HPCG (red). The tables are both adjusted to show Gflop/s for comparability purposes.
It's interesting to see that the same systems that performed very well on HPL are also the top performers on HPCG, although the benchmark throughput scores are orders of magnitude different. To me, this means that these systems are well designed and balanced.
Stay tuned for more results, more analysis, and more fun from the Student Cluster Competition, 10th Anniversary Edition...
