This article is more than 1 year old
Nvidia: Eight bits ought to be enough for anybody ... doing AI
New machine-learning-tuned Pascal GPUs are gonna party like it's 1989
Analysis Nvidia has designed a couple of new Tesla processors for AI applications – the P4 and the P40 – and is talking up their 8-bit math performance.
The 16nm FinFET GPUs use Nv's Pascal architecture and follow on from the P100 launched in June. The P4 fits on a half-height, half-length PCIe card for scale-out servers, while the beefier P40 has its eyes set on scale-up boxes.
The new pair are aimed mainly at inference work, ie: you give the hardware a trained AI model, some suitable software, and input data like video from a camera or sound from a microphone, and it spits out decisions, speech-to-text translations, object classifications, and so on.
We've reached the stage now where deep-learning models are so elaborate – having being constructed on powerful systems using mountains of training data – that the inference side has to catch up: you need a decent number-crunching processor to push information through a complex neural network to make decisions in real time.
That's good news for Intel, Nvidia and others because it means they can sell high-end chips for training and inference, but bad news for us punters: it means more and more data must be shipped off to the cloud, processed there, and the results shipped back to our phones, tablets, gadgets and gizmos, increasing our reliance on stable internet connections and trust in far-away platforms.
Roy Kim, a senior Nvidia product manager, told us the way forward is a "hybrid" approach, with a less-accurate model on the device so that decisions can be made immediately while a more powerful backend processes the situation and returns a more nuanced decision. State-of-the-art image-recognition systems have more than 150 layers of neurons, said Kim, hence the need for some more oomph on the inference side.
What's new?
To maximize inference throughput, so your IoT personal-assistant-in-the-cloud doesn't leave you hanging for too long when you ask it a question, Nvidia has added two instructions to its Pascal architecture: IDP2A and IDP4A. These perform two and four-element 8-bit vector dot product calculations with a 32-bit accumulation.
If I was a moron hack I would right now wax lyrically about Nvidia embracing the good old days of the 6502 or Z80, but I'll spare you that crap. Basically, data scientists say 8-bit precision is fine for neural networks, and that allows GPUs to shuttle around more bytes than they would if they were crunching wider 16-bit or 32-bit values. You don't need that level of precision when rippling input data through deep levels of perceptrons.
Google's TensorFlow-accelerating ASIC uses eight bits for inference, we understand. And Intel and AMD chips can also blast through 8-bit vectors.
Dot what?
Vector dot products are at the heart of artificial neural networks. At the core of all the AI hype at the moment are strings of math equations – dot products and other formula – that extract features from input data, or in plainer English, identify interesting things in information from sensors, cameras and so on, so that software can act on it. This is done by assembling, or training, a network that data flows into and trickles along various paths with different weightings on them, until an answer is formed. The weights are assigned during training to detect features in incoming data.
You can find a gentle introduction to how this works over here, and more involved tutorials here and here [PDF].
The diagram of a single neuron below looks horrific but it's not as scary as you think. You've got values x1 to xn coming in on the left along n paths. Each xi input value is multiplied by its path's weight wi, and then the results of these multiplications are all added up. That's the dot product part. Then that sum is fed into a threshold or activation function, and that output is fed into the next perceptron in the network.
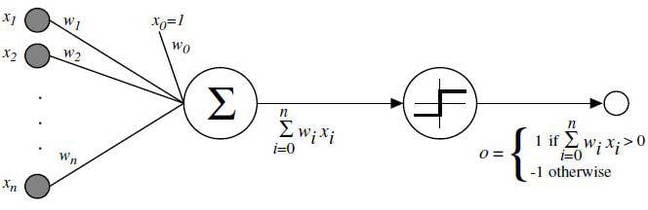
When you link these together you get something looking like this basic network, which has two inputs, three neurons, and an output.
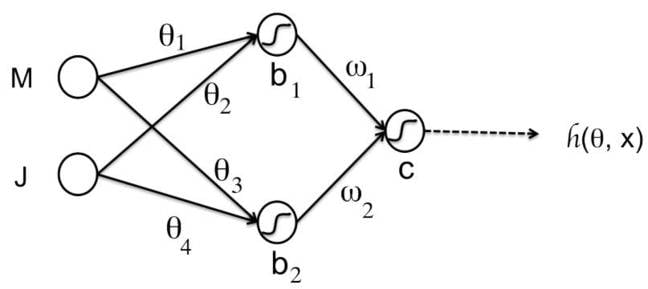
Let's take just the top neuron. It takes the M input value, multiplies it by the weight θ1, and adds the result to J multiplied by θ2. It takes that sum, runs it through an activation function, and feeds the result into the furthest right neuron.
So, ignoring the activation function, that top neuron's dot-product output is: (M x θ1) + (J x θ2). Now imagine those variables are each 8-bit integers ranging from -127 to 127, or 0 to 255. Now imagine doing up to 47 trillion of those dot-product operations a second, all combining inputs to feed into the next stages of a network. That's what Nvidia's P40 is claiming to do. That's what Nv means by accelerated 8-bit dot product calculations.
Nvidia also claims its P4 can do, at its very best, 21.8 trillion operations a second using 8-bit integers, and that the P4 is "40 times more efficient" than an Intel Xeon E5 CPU in terms of the number of images classified per second per watt using an AlexaNet-trained model.
That's after you've taken your AI model and squashed it down to 8-bit weights. This apparently works well for models trained to recognize speech, and is also good for classifying images and similar inference work.
Here's the full specs for the Tesla GPU range including the new P4 and P40:
| Tesla Accelerator | Tesla M4 | Tesla P4 | Tesla M40 | Tesla P40 |
| GPU | Maxwell GM206 | Pascal GP104 | Maxwell GM200 | Pascal GP102 |
| Streaming
multiprocessors |
8 | 20 | 24 | 30 |
| FP32 CUDA Cores / SM | 128 | 128 | 128 | 128 |
| FP32 CUDA Cores / GPU | 1024 | 2560 | 3072 | 3840 |
| Base Clock | 872 MHz | 810 MHz | 948 MHz | 1303 MHz |
| GPU Boost Clock | 1072 MHz | 1063 MHz | 1114 MHz | 1531 MHz |
| INT8 TOP/s | NA | 21.8 | NA | 47.0 |
| FP32 GFLOP/s | 2195 | 5442 | 6844 | 11758 |
| FP64 GFLOP/s | 69 | 170 | 213 | 367 |
| Texture Units | 64 | 160 | 192 | 240 |
| Memory Interface | 128-bit GDDR5 | 256-bit GDDR5 | 384-bit GDDR5 | 384-bit GDDR5 |
| Memory Bandwidth | 88 GB/s | 192 GB/s | 288 GB/s | 346 GB/s |
| Memory Size | 4 GB | 8 GB | 12/24 GB | 24 GB |
| L2 Cache Size | 2048 KB | 2048 KB | 3072 KB | 3072 KB |
| Register File Size / SM | 256 KB | 256 KB | 256 KB | 256 KB |
| Register File Size / GPU | 2048 KB | 5120 KB | 6144 KB | 7680 KB |
| Shared Memory Size / SM | 96KB | 128KB | 96KB | 128KB |
| Compute Capability | 5.2 | 6.1 | 5.2 | 6.1 |
| TDP | 50/75 W | 75 W (50W option) | 250 W | 250 W |
| Transistors | 2.9 billion | 7.2 billion | 8 billion | 12 billion |
| GPU Die Size | 227 mm² | 314 mm² | 601 mm² | 471 mm² |
| Manufacturing Process | 28-nm | 16-nm | 28-nm | 16-nm |
The P4 and P40 will go on sale in October and November, we're told. If you really want to get your hands on similar kit now, Nv's Pascal-based Titan X graphics card, which emerged in July, can also do 44 TOPS of 8-bit integer operations. The P40 is basically a slightly beefier Titan X.
Meanwhile, Nvidia has released TensorRT, an inference engine to run on its hardware, and a software development kit called Deepstream, which can identify people and objects in high-resolution (HEVC, VP9) video. ®
