This article is more than 1 year old
Intel's Broadwell Xeon E5-2600 v4 chips: So what's in it for you, smartie-pants coders
New instructions, transactions, virtualization features and more
Caching the addict
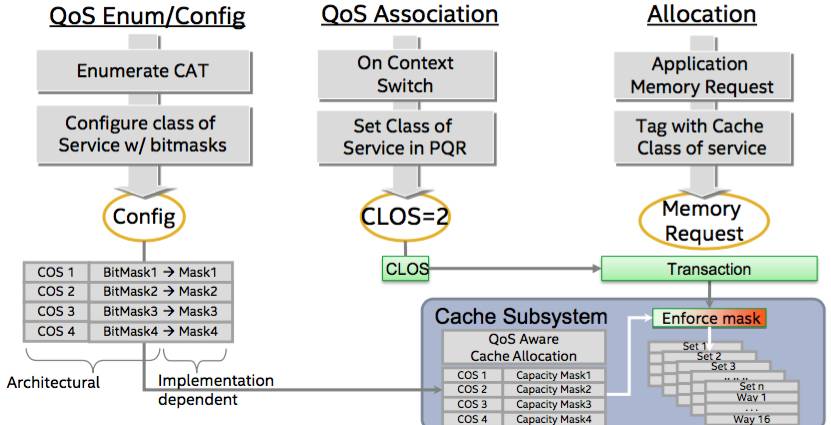
Intel has a set of features it snappily calls Resource Director Technology. This basically lets operating systems monitor cache usage by software. Threads, processes or whole virtual machines can be each assigned a Resource Monitoring ID (RMID) by the OS. When a thread is scheduled to run, the kernel takes its RMID, and writes it to a special per-core CPU register (IA32_PQR_ASSOC aka PQR). During that thread’s execution, any memory it accesses is logged using the RMID in PQR.
Later on, the kernel can retrieve from the CPU telemetry for a given RMID, thus allowing it to read off, for example, L3 cache occupancy. Broadwell server chips support twice the number of RMIDs as Haswell cores, and can monitor memory bandwidth use, too.

Another part of this is Classes of Service (CLOS). A kernel can program the processor with a set of quality-of-service (QoS) classes, each one defining a level of cache occupancy. On each context switch, the kernel assigns the next-to-run thread, process or virtual machine a class ID again using the PQR register. When the thread accesses memory, the processor takes its class ID and looks up the corresponding cache capacity limit for that class. It then applies this limit to stop a thread or process from thrashing, say, the L3 cache with a copy loop and flushing out other data.
The home stretch: Virtualization updates
The Xeon E5 v4 features posted interrupts, which Intel has been making noises about for a while now. These allow a hypervisor to route hardware interrupts directly into a virtual machine. Normally, when an interrupt triggers, the running guest virtual machine is forced to stop and the hypervisor takes over to handle the hardware request – this VM exit is a time-consuming operation taking hundreds of CPU cycles to complete. The hypervisor then has to take care of the interrupt itself or schedule a virtual machine to process it.
Posted interrupts allow the hypervisor to program the CPU to make interrupts fire straight into the guest directly and be handled within the VM without having to exit to the hypervisor. Posted interrupts can also be staged so that the currently running VM continues to finish its high-priority work, and the guest assigned to servicing the latest interrupt is scheduled next. This means the hypervisor can avoid switching between VMs every time an interrupt fires, which improves latency.
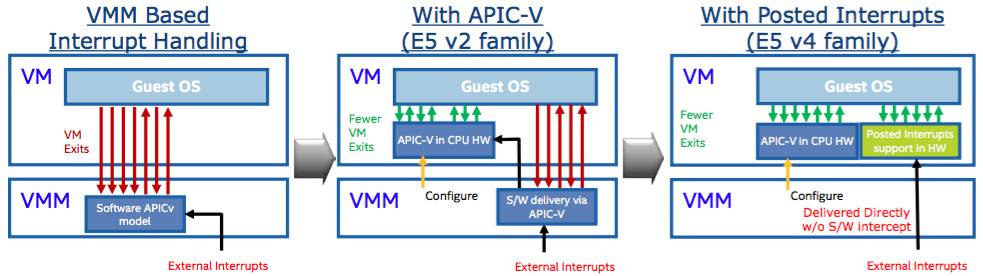
The benefit of this should be obvious: it means virtual machines can react way faster to hardware events, boosting performance for latency sensitive jobs. Intel sees posted interrupts as an essential ingredient in Network Functions Virtualized (NFV) systems, which move computer networking workloads out of hardware and into software. A virtual machine handling packet switching duties must be able to react immediately to incoming interrupts, and cannot wait for a hypervisor to stop it, process the interrupt, and reschedule it. With posted interrupts, it will receive alerts from the hardware without a VM exit.
Using posted interrupts to send ethernet card interrupts direct to a virtual machine running the netperf benchmark, Intel says it was able to shift 41 per cent more data a second compared to a non-posted-interrupt system when using 256-byte packets, and a 19 per cent boost when using 1KB packets.

Posted interrupts are described in detail in this Intel manual [PDF, section 5.2.5].
Another virtualization enhancement is Page-Modification Logging. Whenever software modifies a page of memory, the processor sets a “dirty” bit for the page’s entry in the system’s page table structures. This feature has many uses, one being knowing which pages to write to disk when swapping, and another being discovering which pages to send when migrating a running application from one machine to another.
If you’ve got a program running on server A, and you want to live migrate it to server B, and server B has the program’s read-only executable and initial state already in memory, you only want to send the changed pages to make the transfer as swift and as painless as possible.
Crawling through the page tables checking for all the dirty bits is a chore for the kernel or hypervisor, especially during a live migration. So Intel’s Page-Modification Logging (PML) maintains an in-memory log of altered pages that can be grokked faster than the paging structures.
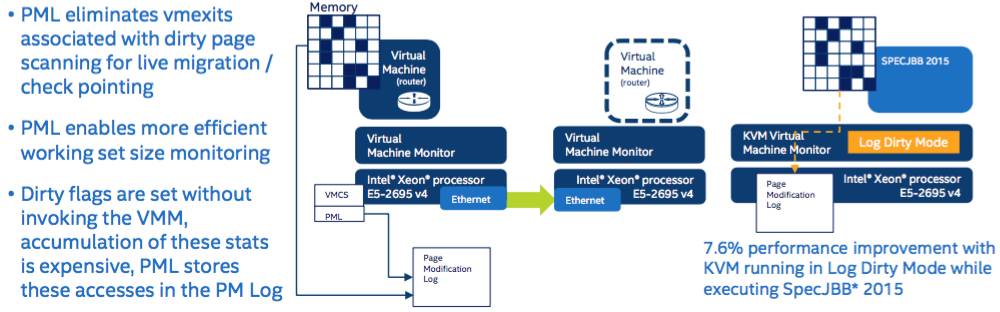
Intel is keen to develop its live migration tech because, again, this is a crucial piece in NFV. One of the selling points of software-defined networks is the ability to move and scale out workloads to meet demand. If a migration takes too long, the telco customer may wonder why they bothered binning racks of dedicated switch hardware for generic servers that supposedly offer flexibility but simply can’t keep up.
Odds and sods
What else? The Xeon E5 v4s will have Hardware Controlled Power Management (HWPM), which involves the processor taking, well, power management out of the operating system’s hands and doing it itself. This is configurable, it can be turned off, and the OS can drop hints on how the CPU should be balancing power consumption and performance. Basically, HWPM lets the processor pick a better P-state by itself.
Finally, there's new Processor Trace features for in-depth debugging: it can write packets to memory describing branches taken and events encountered by software, can filter execution tracing by the pointer in the control register CR3 and whether or not it's in user or kernel mode, and other hardcore stuff for low-level developers.
Your humble hack is wary of vendor-supplied benchmarks, but will leave you with this graph from Intel to put the Xeon E5 v4 family in context – it compares the new E5-2699 v4 with the E5-2699 v3.
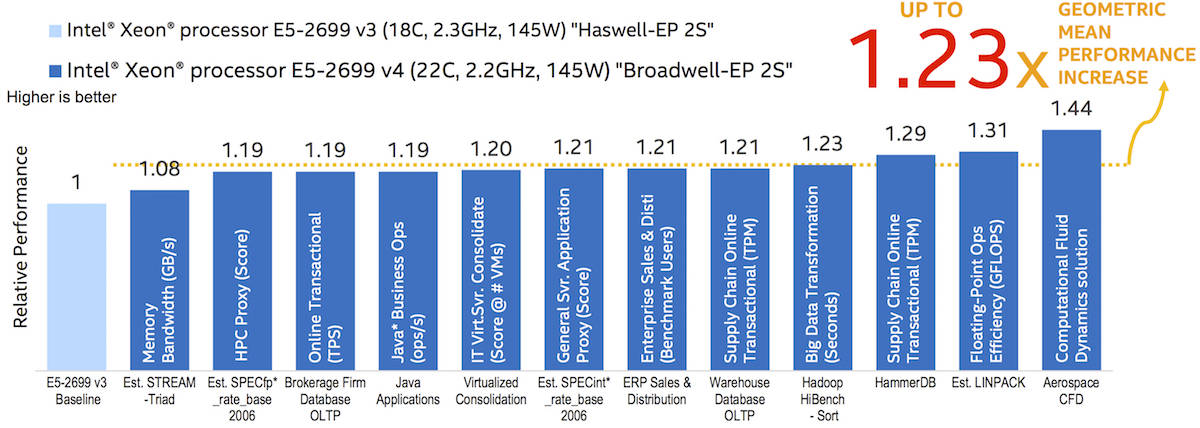
It shows about a x1.2 increase in performance from the v3 Haswell to the v4 Broadwell for various benchmarking tests, when using 22 versus 18 cores. A lot of the above-mentioned features were first seen either in last year's Broadwell parts, or in Haswell, which is the tock to Broadwell's tick. The E5-2600 v4 range essentially takes a mounting pile of micro-architecture improvements, and packages it for scale-out servers – machines to build clouds and software-defined networks.
That just about sums up the new E5-2600 family: it's another Xeon. You put it in a box, and you plug it in to the internet. It's inoffensive. It beats components from two or three years ago to catch the eye of IT bods looking for a hardware refresh, while teasing developers with goodies like posted interrupts, working TSX, and new crypto-friendly instructions. It doesn't really need to do any more than that. That's life when you own 99 per cent of the data center compute market. ®
