This article is more than 1 year old
Solving the data silo problem using a crawl-walk-run strategy
Primary Data opens its tech kimono wider
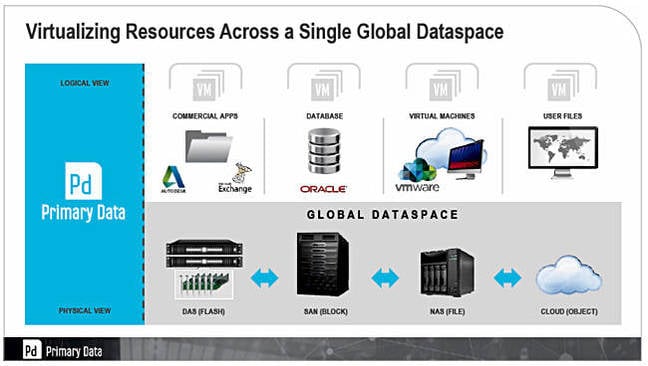
Analysis + Comment DataSphere is Primary Data's product and it provides a storage abstraction layer presenting a single interface to multiple individual storage silos. Primary Data told us more about it at a Silicon Valley IT Press Tour event in early December.
CEO Lance Smith said the company's technology virtualised data, not storage, and enabled users to place data in the available storage silos – DAS, SAN, filers and the cloud – according to objectives they assign to data. File, object and block accesses are supported.
He said storage virtualisation is making larger storage containers from smaller ones. Scale-out NAS is similar. Data is still confined to a silo – you've just made the silo bigger. Storage virtualisation is a failed concept.
Flash is key catalyst and an enabler; you can put metadata in it, away from capacity storage, instead of storing it with data on disk. It has very low latency lookup. In general, the more complex the control plane the slower the access, and that is why NFS is slower than block storage, because of the file system.
We were told about the idea of a unified data space, not necessarily one namespace, with non-routable things routed through an intermediary. DAS is exported as local NAS. If the client is on the same server box this short-circuits the NAS stack. Primary Data has built this into the Linux kernel.
Regarding block storage, a second layer of metadata does block allocation and mapping, using Linux's XFS filesystem, so block can talk objects (like a DNS look-up). It's treated as a look-aside but, when talking to blocks, you go directly to them.
Smith said caching, backup, archive and scale-out are all aspects of the data silo problem. Once you pull metadata out and can map and move data you have solved that problem. "Hyperconvergence is just another symptom of the same problem. We can map and move the data between the DAS. We do a better job at hyper-converged than the guys scattering blocks everywhere."
There are only three OS's that matter – Windows, Linux and ESX. The DataSphere portal can be embedded in these OS's or can be a separate service for talking to legacy systems.
The data mover (agent used to pump data around) and accessors gave full continuous read and write access to data while it is being moved.
Smart Objectives
He talked about Smart Objectives, Primary Data-speak for SLAs, and said the objectives for data are what users want. He discussed two categories:
- Performance – meaning IOPS, bandwidth and latency
- Protection – durability, availability, priority, recoverability, expiration and security
"Any piece of data can be anywhere. How do you add sanity to that? We created a language of objectives to let data objects express what they need from the storage (durability/latency/protection/performance/expiration/ etc.) It's next level QoS. Any aspect of storage could be so expressed. Objectives could be put on the data, on volumes, etc. [and different] users of data could have different objectives for the [same] data."
Objectives can be assigned to files, folders, shares and directories. Different parties can express what they need, like service-level objectives. Ultimately every storage dimension has target values and these get mapped to SLAs with the price dimension. You can manually choose where to put data or the system could determine where to place it based on arbitrage between users, noting who is willing to pay the most to achieve their objective.
A Smart Objective (SO) could be expressed like this: if IOPS go >80K, put data in mission-critical tier. If idle after <time-period>, move it to a lower tier. If there is really low access, then move it to cloud. The DataSphere system locates and moves data. SO's show up in vSphere as VASA policies.
SO has a another aspect: limits and quotas for users/shares/admin domains to use so much data at particular service levels. It's a way to sub-divide resources down logically.
Note a backup is a snapshot with different objectives, and the data is still in the single data space.
Performance dimensions are automatically monitored to see what clients actually achieve.
Everybody basically wants platinum service but most applications can't afford it and don't really need it. Primary Data's economic arbitrage concept provides a market-like approach to automatic data placement. Users/applications that are willing to pay for a better data service level get it in preference to ones that don't value that service level enough.
The DataSphere system can deliver levels of priced data services to applications, such as:
- Platinum – highest performance, lowest latency, low capacity – $$$$$
- Gold – highest performance, low latency, medium capacity – $$$$
- Silver – mid-performance, some latency, large capacity – $$$
- Bronze – slower performance, more latency, various capacities – $$
- Cloud – slowest performance, highest latency, huge capacity – $
Storage capitalism is like market economics. Individual storage objects are tenants. Storage devices are landlords. It's a supply and demand thing.
Parallel NFS and releases
DataSphere has a parallel NFS (pNFS) influence, and Primary Data says pNFS provides a way to split control and data planes and gives you an out-of-band control path to silos including DAS, PCIe storage and in-memory storage. Founder and CTO David Flynn said, "We're taking the best of the pNFS environment (the plumbing) and leaving the rest behind ... Our solution is not pNFS-specific. It works with SMB. Agent (data portal) is a filter driver in Windows and reroutes data as needed."
Primary Data characterises its DataSphere release schedule as embodying a crawl, walk, run strategy.
DataSphere releases:
- DataSphere 1.0
-
- vSphere 6.0 and VVOL support
- Economic arbitrage
- Smart placement
- Smart objectives
- Second release
-
- VMware vSphere 5.5 support
- Third release
-
- Scale-out NAS support
- Subsequent release
-
- Data migration like NetApp Data ONTAP to CDOT (18 months out)
DataSphere is designed using a cluster of couplets – for high-availability and for namespace. Being able to federate between two DataSphere clusters is a roadmap item.
The pricing model is subscription with two versions of product: a starter pack starting as low as $25K/year and a more expensive enterprise level.
Competitive thoughts
David Flynn said; "I don't view anyone as a competitor," but that is every entrepreneur in history thinking their pretty baby is unique. He places DataSphere in the top right-hand quadrant in a competitive quadrant of diversity:

Speaking more specifically, he thinks the copy data management people have the wrong idea: "Copy data management is like adding another layer – you've fundamentally given up – [with] Actifio, Delphix – storage is functionally broken because data and metadata are co-resident. Storage is fundamentally broken."
Here's Flynn's view on the Dell-EMC acqusition: "Dell is buying EMC for enterprise entry and EMC is looking for growth. But the two have massive silos and our data virtualisation can sort that out. It can allow Dell and EMC kit to sit side by side and load-balance between them and present them as one virtual resource."
On EMC's ViPR, he says: "ViPR had good goals but its track record in success was difficult. CoprHD is an attempt to get open source community to work out what to do with it."
Concerning ScaleIO, DataSphere is compatible with scale-out apps like Hadoop. ScaleIO uses consistent hashing to splash blocks around the set. Ditto VSAN, [which] remains as shelfware, as hot node causes other nodes to be hot as well and run full tilt, i.e., with 3 replicas. Consistent hashing means data spread is across the set and nobody gets locality.
DataCore's SANsymphony product supports VVOLs and can effectively add a VVOL-supporting interface to any third-party arrays virtualised behind SANsymphony, whether they support VVOLs themselves or not. Flynn says: "Datacore VVOL'ises legacy gear but does it in the data path," which he thinks is not the best thing to do; the control and data paths should be separate.
Comment
Primary Data's technology is well thought out and logical; elegant even. You buy its software and some flash-enabled servers to set up a separate storage metadata management system. It acts as a kind of over-all, multi-array, multi-device, on-prem and off-prem (cloud), multi-vendor storage controller which operates out-of-band.
The pitch is that enterprise storage is broken, and adding more and more silos to fix the problems of existing ones gets you into a complexity and cost dead-end. Yes, you need more than one storage tier and more than one quality of service, but all the tiering and data moving and data placement and protection and so on should be provided through a single all-embracing, metadata-based interface.
Primary Data's ideas are antithetical to those of other silo-melding startups, such as Actifio, Delphix, Rubrik and others. If the company's product strikes a chord with hard-pressed and fed-up enterprise CIOs then Primary Data will do well. Competitors may well say it's overkill, that you still need multiple silos underneath DataSphere's abstraction mask, and that, for example, unifying all secondary data silos onto one system is a simpler and more cost-effective way of dealing with broken enterprise storage.
Only enterprise CIOs know which approach is best and, as they vote with their corporate wallets in 2016 and 2017, we'll get a chance to see how this silo-busting and melding side of storage is panning out. ®
