This article is more than 1 year old
Facebook SSD failure study pinpoints mid-life burnout rate trough
Burnouts peak early, then fall, before increasing with age. Like journalists, then
Facebook engineers and Carnegie Mellon researchers have looked into SSD failure patterns and found surprising temperature and data contiguity results in the first large-scale SSD failure study.
In a paper (PDF) entitled A Large-Scale Study of Flash Memory Failures in the Field they looked at SSDs used by Facebook over a four year period, with many millions of days of usage. The SSD suppliers mentioned were Fusion-io, Hitachi GST, Intel, OCZ, Seagate and Virident.
Individual suppliers were not revealed in the tables and charts. Instead we have:
- Platform A – 720GB – PCIe gen 1 4-lane
- Platform B – 720GB – PCIe gen 1 4-lane
- Platform C – 1.2TB – PCIe gen 2 4-lane
- Platform D – 1.2TB – PCIe gen 2 4-lane
- Platform E – 3.2TB – PCIe gen 2 4-lane
- Platform F – 3.2TB – PCIe gen 2 4-lane
According to one chart in the 14-page paper, platform D appeared to have more errors than the others, with platform B having the least.
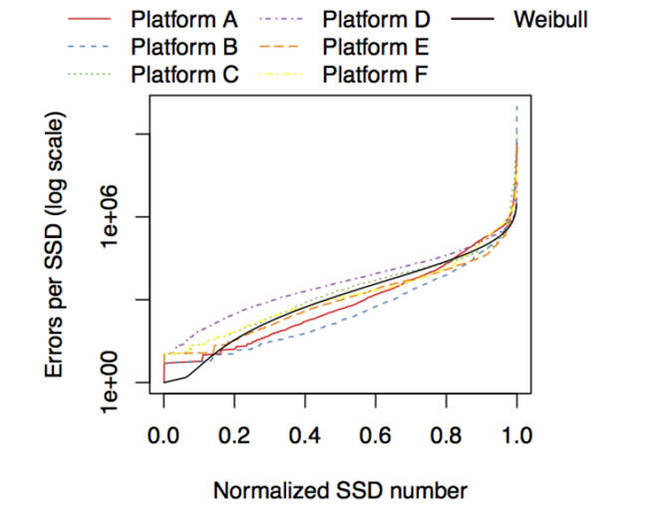
The distribution of uncorrectable error count across SSDs. The total number of errors per SSD is highly skewed, with a small fraction of SSDs accounting for a majority of the errors.
One finding was that SSDs do not fail at a steady rate over their life, instead having periods of higher and lower failures.
Another was that SSDs that have read the most data do not show a statistically significant increase in failure rates. Higher temperatures led to higher failure rates with data write throttling (reduction) reducing the impact of higher temperatures.
Non-contiguously-allocated data leads to higher SSD failure rates, as can dense contiguous data under certain conditions.
They point out that it is necessary to measure data actually written to flash cells in an SSD rather than the data sent to the SSD by the host OS, because of wear reduction techniques and system level buffering.
Over the lifetime of the SSDs studied, failure fell into three phases. These were named early detection, early failure and useful life/wearout, which correspond to the amount of data written to the SSD. The chart shows how failure-rate peaks early, but then falls into a trough, after which it rises steadily as the SSD gets used and ages.
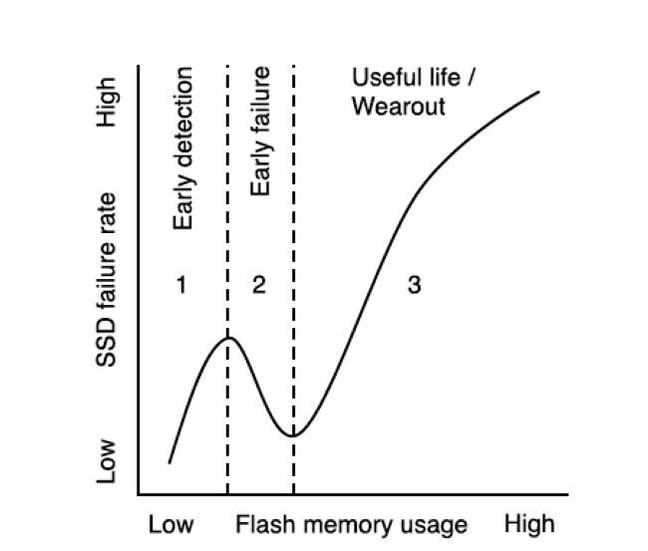
The researchers do not identify any one SSD as better than another, instead looking at the overall failure pattern. They find that techniques like throttling – which may be used to lower SSD temperature – are effective at reducing SSD failure rates. It also seems advisable to avoid non-contiguously allocated data (called sparse data layouts). ®
