This article is more than 1 year old
One bit to rule them all? Forget it – old storage types never die
Pups' guide to running with the storage pack
Cross comparing
Objects stored in an object file system could be an individual text file or an entire VHD. This changes how object storage behaves when thinking about distributed storage systems.
In a block-based storage system you replicate the entire block storage system (LUN, disk, what-have-you) all as a single item. Objects storage doesn't have that hindrance; it cares only about the object. If an object changes, send the new object.
This works really well when you want to store hundreds of millions of photos or text files. When you try to use block storage for large, continually in-use files (VHDs) you start running into the same problem as file systems: do you resend the entre object every time it changes?
Object stores can deal with this in a number of different ways. They can be designed from the ground up for replication, storing VHDs and the like, or they can use a shim.
If they're designed from the ground up for replicating large objects they are essentially somewhere between block storage and object storage. It is either block-aware object storage or it shards large objects.
Block-aware object storage treats large objects as a single object, but anything above a certain size is replicated not as a whole object, but based on which of the underlying blocks (remember the disks under the object storage are still blocks) for that object have changed.
Sharding object storage takes large objects and turns them in a bunch of little objects, and maintains an index of which smaller objects go together in what order to make the larger object. This lets the underlying object storage carry on inefficiently replicating the entire object every time something is changed.
Shims
Shims are a software layer that serve as an interface between the underlying object storage and an operating system or application. Typically shims will emulate a file system. You put a file into the shim and the shim puts it into the object store.
The shim maintains the index that says "bachelor_party_funny_face_limo_photo.jpg is guid deb17e15-d47c-449f-b1b0-4d553e7d143f", just like any other application using the object store. It also replicates all the details of the file system it is emulating, such as permissions, locking and so forth.
This is layered on top of the less feature-rich object storage. This is in many ways no different from how a traditional file system exists on top of raw block storage, except that the underlying object storage is usually doing some pretty complicated distributed replication underneath.
Now shims don't have to replicate a "full" file system. There's nothing saying a shim has to replicate a file system at all. A shim could be something that takes commands in the format of an Amazon API and passes them to the object storage of a third-party object storage vendor.
A shim could also serve up object storage as an NFS or SMB network share, allowing remote computers to consume the object storage as a network file system. Any network file system (NFS, SMB, etc) is essentially a shim between a remote computer and the underlying storage.
The remote computer can't tell if the underlying storage behind the network file system protocol is a traditional file system running on raw block storage or a network file system shim running on top of object storage.
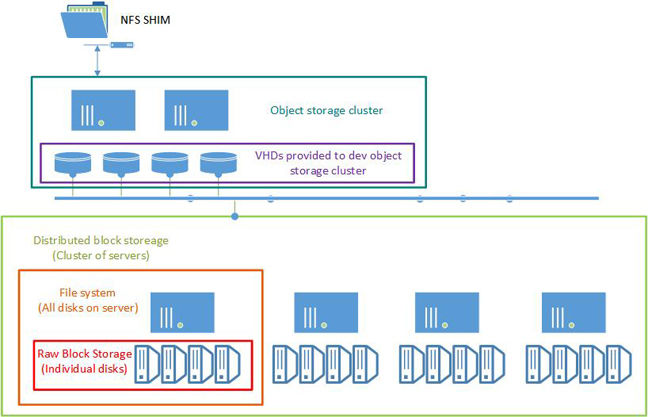
As an example, consider the above image. Here the NFS shim is connected to an object storage cluster that is itself consuming VHDs presented by a distributed block storage cluster running on top of a node-level file system that runs on top of raw block storage at the individual disk level. Such a stack of turtles is not as unlikely as you'd think; I've seen such things in production.
