This article is more than 1 year old
HPC boffins: Our HOT MODELS will help you cope with DISASTER
What'll happen if the tornado hits? Glad you asked
![]() HPC Blog What’s the most common and costly type of natural disaster? If you answered "floods and tsunamis” you’d be right on the money.
HPC Blog What’s the most common and costly type of natural disaster? If you answered "floods and tsunamis” you’d be right on the money.
Economic damages caused by large and small flooding events – either caused by storms, storm surges or earthquakes, in the case of tsunamis – are truly massive, running into the billions or tens of billions per event.
Let’s say that you own the entire Earth. If that were the case, you’d definitely want flood insurance. But which areas should you cover, and how much should you pay for it? I’ll bet you don’t know the answers to those questions, so maybe you’re not so clever after all, right?
A great place to start might be KatRisk, a company founded in 2012 by “one geek, one scientist, and one engineer”. Its mission is to build comprehensive and highly detailed risk models that will give governments and businesses a much clearer picture of the disaster risk associated with particular locations.
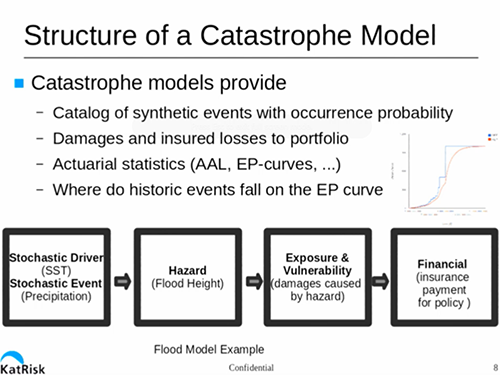
In their GTC14 session, company co-founder Dag Lohmann discussed the reasons why catastrophe modeling is important and difficult. While these events cause huge damage, they’re infrequent, so historical data isn’t a very good guide to how badly an event might impact a particular location.
For example, in the US, North and South Carolina are located in an area that could be hit by a large hurricane, but haven’t had a direct hit in decades. How much damage could a hurricane cause in these states? Where would the damage be the worse? Difficult questions to answer, given the lack of historical data.
KatRisk’s overriding goal is to model worldwide flood maps at 10-90 metre resolution. Given that the world is a big place with a lot of rain, this is quite a computational problem.
Water, water everywhere
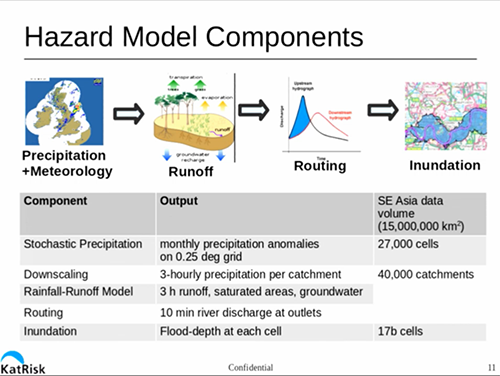
To build this model, in general terms, you need to model the amount of precipitation falling in a particular area, the amount of water that is carried away by rivers, the location/depth of the remaining water, and how long it stays around.
This is a cubic problem, meaning that if you decrease your required resolution by a factor of two (say from 100 to 50 metres), you increase the runtime for the model by a factor of eight. They’ve written their code to run under CUDA, giving them an speed up of 50-200x vs a single core general purpose CPU.
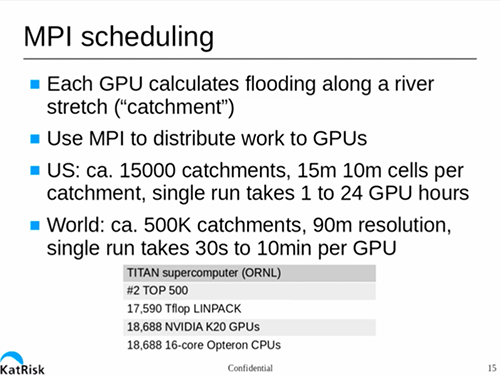
But even running KatRisk models on a brace of beefy GPU-equipped workstations can take from weeks to years, depending on the size of the area and resolution.
Fortunately for KatRisk, they have been able to get time on ORNL’s Titan supercomputer, giving them access to a seriously huge number of K20 GPUs and 16-core AMD Opteron CPUs. This has vastly speeded up the process of modeling US flood risk/impact, and improved the resolution as well.

This session provides a fascinating look into how catastrophe models are constructed and how today’s technology allows us to have more accurate models. If you have an interest in modelling, or work in the insurance industry, this session is a must-see. Check it out here. ®
