This article is more than 1 year old
Clueless over your heaps of unstructured data? You could soon whip out 'DIY tool'
El Reg looks into Data Gravity's new work
Analysis DataGravity appears to be working on a kind of GUI-driven SQL for unstructured data so small to medium businesses can run data analytics, possibly without having to hire data scientists – although this has not been confirmed.
After studying a DataGravity blog closely, along with other blogs and reports around the 'net, Vulture Central thinks it has sussed out what the startup is about at a high level.
DataGravity is a startup founded by Paul Long, who founded EqualLogic and John Joseph, an EqualLogic marketing and product management exec, after Dell purchased EqualLogic for $1.4bn in 2008.
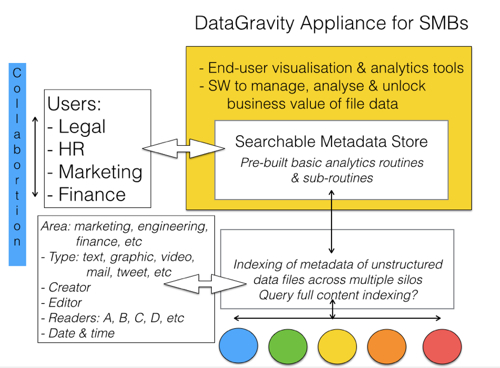
What we appear to be looking at is a DataGravity appliance for small and medium businesses (SMBs) which are accumulating unstructured data stored in multiple silos that can be on-premises, in remote offices or in the cloud.
Business users in departments such as HR, marketing, sales, legal, and finance may want to look into files to find out, for example, why recruits of a certain type perform better than others, or which social networking posts ultimately generated the most cash, and so on.
These are ad hoc queries which can not be easily generated using SQL; the data is not structured and the end users don't know and don't want to know SQL.
They want to sit at a screen and use a powerful but easy-to-understand GUI to pull up all sorts of information and images stored in multiple files across many different storage systems around the company. They don't want to run individual, manual searches of mail records and so on, when a single search for, say, "oil + gas" plus "marketing" should suffice.
So DataGravity's appliance, we surmise, will enable them to analyze when their company sold into the oil + gas market, who did it, who helped, to what degree, what worked and what didn't, and in real-time. The idea is to build on existing expertise and resources in the company to make faster and better decisions and improve the business's performance.
DataGravity analytics schematic diagram.
OK, how can it do this with the source data scattered all over the storage landscape in different locations, arrays, and filetypes, in real-time. There's no way it can do this of it has to look in all the target arrays and files, none, nada, zip.
It has to be a search of metadata in the appliance. So, logically, that metadata has to be generated by some kind of bot trawling through the SMB's filestores, and being aware of different file formats and storage facility locations and accesses.
In other words there is a sort of content management system indexing the overall filesystem's metadata and building (here, we're guessing) a structured metadata database. Pre-built analytic routines (aka search requests) can be given parameters by the users, through the GUI, and search the metadata, pulling up the results (aka reports) in real-time.
The users get access to the data and experts they need to help them work out how to things faster sand better. We understand there'll be some kind of collaboration facility for users as well.
One question is whether DataGravity's SW will run full text indexing on unstructured data files? That will greatly widen the scope of analytics search terms but would entail much larger metadata files. It would also mean the users could pull up source data; mails, documents, videos, images, contact details, whatever.
Another question is how DataGravity customers will be able to get significant wins early from using the software. We'd guess that search universe and search types would initially be restricted to the most promising data areas.
DataGravity exhibited at the recent VMware PEX in Las Vegas and is recruiting partners. We expect product announcement later this year.
A cautionary note: all of the above is what we have worked out from what material is available. Read DataGravity's blogs and see what you think. ®
