This article is more than 1 year old
Hey coders – get a sense of hUMA: AMD to free GPU from CPU slavery
Peer-to-peer architecture for server, desktop and mobile processors
AMD is to manufacture microprocessors that connect their on-board CPU and GPU components more intelligently than ever before.
The upcoming chips will utilise a technique AMD calls Heterogeneous Queuing (hQ). This new approach puts the GPU on an equal footing with the CPU: no longer will the graphics engine have to wait for the central processor to tell it what to do.
Currently, the CPU alone manages application tasks, pulling in work from job dispatch queues in user memory. It can even assign tasks to itself, one core scheduling work on another core, for instance.
The GPU doesn’t have these capabilities. Typically it is managed as a peripheral resource by way of the operating system and driver software, a pathway that adds considerable latency to GPU access.
The reasons for this are largely historical: the GPU was originally a separate chip mounted on an add-in board plugged into the main system bus. This model hasn’t changed – even though the GPU is now integrated into the CPU package and may even be part of the same die.

The old way: the GPU is slave to the CPU and can’t manage its own task queues
AMD’s new approach, the result of its work defining what it calls a Heterogenous System Architecture (HSA), grants the GPU the same memory access and work management capabilities and as the CPU has.
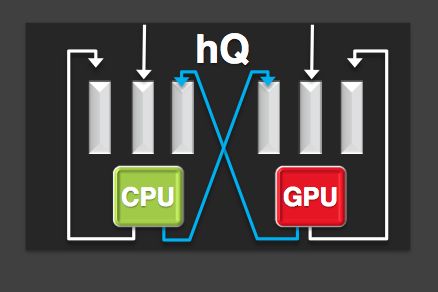
An hQ GPU, then, can monitor task queues to accept and schedule tasks, for both itself and for the CPU. Applications with work for the GPU just bundle up the job details and add it to the GPU’s dispatch queue in user memory. The kernel level driver path is eliminated and with it all the latency that currently exists.
At the heart of the system is AMD’s Heterogenous Unified Memory Architecture (hUMA) in which user memory is shared by the CPU and the GPU. However, a new addition is a standardised task dispatch packet format able to be understood by any HSA-compatible hardware, likewise a standard queue format. Apps can generate tasks in this new packet format directly, and there’s no need to translate the packets into intermediate or vendor-specific formats, which is one of the jobs drivers are currently required to do.
No longer having to translate and make copies task packets improves performance. So does having direct access to task queues in user memory because there’s no longer need for the latency inducing kernel mode changes imposed because the driver must operate in a protected memory space.

Equal cores: the Heterogeneous Queuing architecture
Enabling the hQ GPU to operate independently of the CPU creates more opportunities for the latter to be put to sleep while the GPU is rendering pixels and polygons, or crunching numbers as a massively parallel data processor. As such, says AMD, hQ’s benefits neatly scale from smartphone processors all the way up to data centre chippery.
Of course, all this only makes sense if more than one vendor is supporting the initiative, so AMD was quick to point out the HSA packet format is backed by its fellow HSA Foundation members, among them ARM, Qualcomm, Samsung, Mediatek and Texas Instruments.
There ought to be no shortage of HSA-compatible hardware, then, but will applications take advantage of it? AMD hopes its efforts to embed HSA into standard APIs such as OpenCL and OpenCV, allowing coders to benefit from the new approach without effort.
“We also plan to connect HSA through popular programming models such as Java and Python... and that delivers some of the benefits,” said AMD senior fellow Ben Sander.
“But you can use this stuff directly. That requires more investment by the programmer but you’re getting the ultimate control over the package and what’s sent to the GPU.”
What AMD isn’t saying, however, is when it will implement hQ in its own processors. ®
