This article is more than 1 year old
Tell me, professor, what is big data?
A whole different dimension, says data scientist Mark Whitehorn
Mean machine
Suppose you manufacture combine harvesters. You notice that sensors are getting very cheap, so you think about covering your next model in sensors (temperature, vibration, pressure, GPS and so on) that can stream data back to headquarters.
OK, before you go any further with this article, stop and think about what use we could make of that data. Try to think outside the box.
In no particular order we could:
- Track the position of the combine in a field, look at the yield per unit area and use that information to give the farmer valuable information about how to, for example, distribute the fertiliser for next year, drain the field and so on.
- Use the yield patterns to predict when the combine will be full so that it can actively communicate with the tractors and trailers that collect the grain and they can turn up at the appointed time and exact place.
- Data collected over several years could be used, along with weather data, to predict the yield in any one year for the entire field.
- Combines are very expensive bits of kit that are used infrequently during the year but intensively in the summer. A broken combine can cost a fortune in lost revenue and missed harvest. It is now possible to scan the sensor data looking for temperature and vibration patterns that are characteristic of an imminent component failure and get the part shipped and fitted before it fails.
- Driving habits can be closely monitored, cross-correlated with fuel consumption and used to advise on driving style and technique.
- The machine can be set to shut down if it moves outside a given area (in other words, is stolen).
Of course, crop growth is influenced by a multitude of factors, not just fertiliser, so if only we fitted a probe that took moisture samples we could …
And so it goes on. Much of this is already being done (Google "telematics combine harvesters".)
Another characteristic of big data is not simply how we collect the data, but why we collect it. In the old days (the small data days) we started trying to answer specific questions such as “how do we track all of our transactions?” and collect the appropriate data to do that.
We have the technology to collect vast amounts of data so the strategy can shift if we want it to
We have the technology to collect vast amounts of data so the strategy can shift if we want it to. We can say: “We certainly could collect all of this data at this kind of cost. If we did so, what could we do with it?”
I hasten to add I am not advocating the collection of data purely for the sake of it. Nor am I suggesting putting in vast arrays of sensors, collecting the data and then trying to work out what to do with it.
I am suggesting that you perform mind experiments where you say, “OK, we now have the technology to collect data such as this. What advantage could we reap if we did so?”
However I am not being dogmatic here. There certainly are times when we have the problem first and big data is the answer.
You have probably heard of the human genome project. A mere $3bn and 13 years work means that we are the only species we know that has sequenced its own genome. Which is, I believe, a major turning point for any species (let’s see the dolphins do that one).
But where does it get us? Well, apart from winning the “cleverest species on the planet” award, not very far. You see, it isn’t usually your genome that gets sick; it is your proteome (the sum of all the proteins in the body).
So work is progressing to baseline the human proteome and I am privileged to be a very small part of that project. Computationally, this is a much, much more complex undertaking.
Why? Well, to identify the proteins you have to chop them up into sections (peptides), pop the peptides into a mass spectrometer (basically a very accurate weighing machine) and measure the amount of each fragment. Then you have to back-extrapolate from the identified peptides (in itself a probabilistic process) to the proteins.
One of the many challenges here is that the mass spectrometers output big data. The output is essentially a trace consisting of about 800,000 XY coordinates. A laboratory with 10 instruments could easily produce in the order of 15 to 20 billion data points per day.
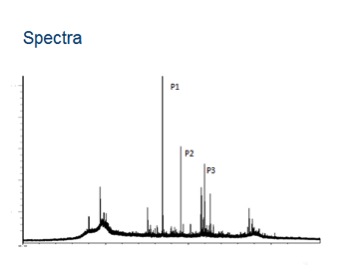
Medical advance
To be technical, the mass spectrometers do multiple scans per second so these are actually three-dimensional peaks. And we have to calculate the volume under the peaks.
So, in this case, we did have a problem to solve and collecting specific big data was the way to solve it. However, once we had the data, all manner of other uses for it became apparent to us.
For example, we could use multiple data runs to watch the individual machines for calibration drift. We could take multiple runs using identical samples and cancel out the noise. We could… and so on.
Big data is real. It has always been there, it will always be there. We now have the technology to deal with it. It will change our lives. It is already doing so – from combines to revolutionising medicine. Get some today. ®
Professor Mark Whitehorn is chair of analytics at Dundee University's School of Computing
