This article is more than 1 year old
Ex-Yahoo! Hadoopers hoover up $50m into trunks
Open source purist Hortonworks sharpens tusks for Hadoop 2.0 battle
What's next
Hortonworks has plenty to spend the money on, that is for sure. "With this funding we will focus on both scaling global field operations as well as further investing in our engineering organization. It will enable us to increase the rate of innovation across all of the Hadoop projects," Bearden wrote in his blog post. "This starts with the YARN based initiatives but also extends to Security, Data Lifecycle Management, Streaming and beyond. Those investments will continue to fulfill enterprise requirements and fuel greater enterprise adoption in the coming months."
To help build excitement for the Hadoop 2.0 stack, and throw a little cold water on the competition, Hortonworks will be releasing a community preview of the Hadoop 2.0 stack that will eventually be commercialized as HDP 2.0 later this year.
Arun Murthy, one of the founders of the company who used to run the Hadoop clusters at Yahoo! before he left, tells El Reg that this stack is going to broaden Hadoop's appeal in myriad ways.
Interestingly, Murthy has been focused on building the follow-on NextGen MapReduce, now known as Yet Another Resource Negotiator, or YARN, to bring other kinds of processing besides batch-mode MapReduce to Hadoop. And he is the final committer for YARN, and that means it is not ready for production until he says so.
There are a lot of big changes coming with Hadoop 2.0, and scalability is a biggie. Apache Hadoop 1.0 basically pooped out at somewhere around 4,000 nodes in a single cluster because of the scalability limits if the NameNode server that keeps track of the triplicate data chunks that are spread across the cluster. (With Hadoop, you spread the unstructured data around and then ship processing jobs off to the data, where it is then chewed on, summarized, and reassembled if a MapReduce job spans more than one chunk of data.)
With Hadoop 2.0, the NameNode, which is a big single point of failure, can have a hot standby and there is also a means of federating multiple NameNodes together for scalability.
Murthy says that you can now federate three, four, or five NameNodes with maybe 4,500 server nodes under each, giving you somewhere between 13,500 and 22,500 server nodes that can have MapReduce or other algorithmic work dispatched to them.
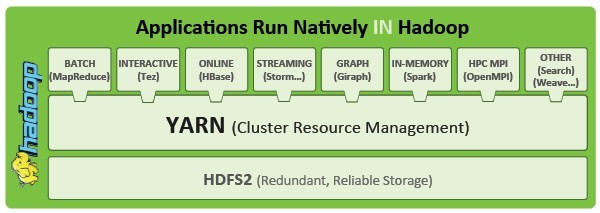
YARN will let Hadoop runs multiple data processing techniques against the same data
With Hadoop 2.0, the data processing algorithms and cluster resource management parts of MapReduce are being broken into two, with YARN being the cluster resource manager and, more importantly allowing for other non-MapReduce data manipulation methods to be added to the framework.
And all of these different data munching techniques – interactive queries, graph analysis, search, even the message passing interface (MPI) technique used in parallel supercomputers – to all plug in and chew on the same data inside the cluster.
Murthy says that YAN has been tested to span between 3,000 and 5,000 nodes already and he is confident, based on simulations, that it will span as far as 10,000 nodes by the time it goes into production.
"I don't want to oversell it because it isn't fully real until we have deployed it somewhere," says Murthy with a laugh.
Of course, that somewhere is likely to be Microsoft or Yahoo! or both.
The Hadoop 2.0 stack will also feature the HDFS2 file system, which will be able to take snapshots of data sets and which will also allow for applications to mount it like an NFS file system. (This is something that has given MapR Technologies a leg up on its Hadoop rivals to date.) This NFS mounting capability does not allow for random writes, but you can do random reads, sequential writes, and appends, of course.
Murthy is making no promises, but says that the Apache Hadoop 2.0 stack is a few weeks from being declared a beta by the community, and it is expected to be generally available by the late summer or early fall. The commercial release of Hortonworks Data Platform 2.0, which is based on this stack of code, will take somewhere from six to eight weeks longer, due to hardening and testing.
In the meantime, Hortonworks is launching a certification program to get applications tested and verified that they work on top of YARN. Hortonworks has also inked a reseller agreement with network storage supplier NetApp, which will see the array maker peddle HDP 1.0 and 2.0 atop its E-Series storage. ®
