This article is more than 1 year old
Enter the Dragon: The Chinese superputer set to win the Top500 crown
Full specs on the 17-megawatt 'Sky River'
The chip that Intel didn't want you to know about
On the x86 portion of the Tianhe-2 system, NUDT has opted for a top-bin Ivy Bridge-EP part, and Dongarra says it is, in fact, a twelve-core Xeon E5 v2 chip (specifically, the E5-2692) running at 2.2GHz. Intel is sure to be annoyed by the release of this information, since it has not announced the core count of these processors. There has been some yammering about a ten-core part up until now, but now we know there is a twelve-core part. Intel is not expected to announce these Xeon E5 v2 processors until the fall, most likely at Intel Developer Forum in September.
But as was the case with the eight-core "Sandy Bridge-EP" Xeon E5 v1 chips, Intel has ramped up production ahead of the formal launch and cherry-picked some big HPC customers to show off the processor. As El Reg said last week, perhaps NUDT will be the only customer showing off the new Xeon parts in HPC iron if Cray is not ready to get the chips into its "Cascade" XC30 and XS300 - formerly Appro Xtreme-X - machines. Appro was the chosen one last time around, Hewlett-Packard is talking too much about Moonshot and ARM servers to be HP's favorite, and Cisco Systems got its turn in the sun with the Xeon 5600 launch four years ago. IBM was looking to sell its x86 server business a few months ago (and still might be so inclined) and has those annoying Power Systems and System z mainframe lines that just won't roll over and die. (They seem to have taken a rest by the side of the road in recent quarters, to be sure, and have lost some of their luster in HPC, too.)
The layout of the Tianhe-2 compute blades is a bit funky, and in a good way that packs more computing elements in a rack than did the Tianhe-1A system from three years ago. And those computing elements – both the Xeon CPUs and the Xeon Phi x86 coprocessors – have significantly more floating point oomph. The result is a lot more flops per rack.
The Tianhe-1A system had the Arch network interface card and two two-socket Xeon processors on the top portion of the compute module and two Nvidia Tesla cards, attached by PCI-Express 2.0 x16 links to the processors, in the bottom portion of the module.

Oops, I think I broke it
With Tianhe-2, the Arch interconnect and two Ivy Bridge-EP compute nodes appear to be on a single circuit board (even though they are logically distinct). The compute node plus one Xeon Phi coprocessor share the left half of the compute node and five Xeon Phis share the right side, and the two sides can be pulled out separately. There's a reason for this.
In the famous picture of the Tianhe-1A super at the National Supercomputing Center in Tianjin that shows a technician pulling out a compute node, the node was so heavy that he actually jammed it and could not get it to slide back into the system.
So this time around, with even more iron in the drawer, Inspur broke the drawer into two halves for easier maintenance. They link through what NUDT called a "horizontal blind push-pull structure," which is a funky way of saying that the circuit board on the compute side has evenly spaced connectors that mesh with ports coming off the back-end of the modified Xeon Phi 3000 Series cards. You pop some mechanism and these connectors open up and you can slide one half of the drawer out to tweak the iron as needed.

The Tianhe-2 Xeon Phi drawer in action
The Xeon Phi cards only support PCI-Express 2.0 connections at the moment, but Tianhe-2 is tricked out in PCI-Express 3.0 x16 connections and is therefore ready for whatever Xeon Phi coprocessor Intel might come up with down the road. (Say, perhaps, a future "Knights Landing" Xeon Phi card with a lot more cores and a lot more oomph and an upgraded Arch interconnect, which is limited to PCI-Express 2.0 at the moment, too?)
Each Xeon E5 v3 node has 64GB of main memory. The 32,000 processors in the machine have a total of 384,000 cores, and at the 2.2GHz clock speed that yields 6.76 petaflops of aggregate peak floating point performance for the x86 portion of the Tianhe-2 machine.
That special version of the Xeon Phi that NUDT is getting is called the 31S1P, and the P is short for passive cooling. Dongarra said that this Xeon Phi card had 57 cores and was rated at 1.003 teraflops at double-precision floating point, and that is precisely the same feeds and speeds as the 3120A launched back in November with active cooling (meaning a fan). That 3120A had only 6GB of GDDR5 graphics memory, and the 31S1P that NUDT is getting has 8GB like the Xeon Phi 5110P card, which has 60 cores activated, which runs at a slightly slower clock speed, and which burns less juice and creates less heat. It is also 33 per cent more expensive at $2,649 in single-unit quantities. Anyway, with 48,000 of these bad boys, the Xeon Phi part of Tianhe-2 has 2.74 million cores and delivers a peak DP performance of 48.14 petaflops. Add 'em up, and you get 54.9 petaflops peak.
The Tianhe-2, like its predecessor, is also front-ended by a homegrown Sparc-based cluster. NUDT has created its own variant of the Sparc chip, called the Galaxy FT-1500, which has sixteen cores, runs at 1.8GHz, is etched in 40 nanometer processes, burns around 65 watts, and delivers around 144 gigaflops of double-precision performance. The front-end processor for the Tianhe-2 machine has 4,096 of these processors in its nodes, which gives another 590 teraflops. But, who's counting?
Dongarra has seen a Linpack parallel Fortran benchmark run on a portion of the Tianhe-2 machine with 14,336 of the nodes fired up and 50GB of memory on each node (that is a strange number); this box had a peak DP performance of 49.19 petaflops, and managed 30.65 petaflops on Linpack, achieving a 62.3 per cent computational efficiency. That is more than enough to take the top slot in the June Top500 supercomputer rankings.
The most interesting part of the Tianhe-2 system is probably the Arch interconnect, which is also known as TH Express-2 according to Dongarra. The heart of the Arch interconnect is a high-radix router, just like Cray's Intel's "Gemini" and "Aries" interconnects, and like Aries is also uses a combination of electrical cables for short haul jumps and optical cables for long haul jumps. And like InfiniBand networks, Arch uses a fat tree topology, which is why many believe that Arch is, in fact, a goosed up version of InfiniBand, but NUDT is claiming it is a proprietary protocol and frankly, we are in no position to argue.
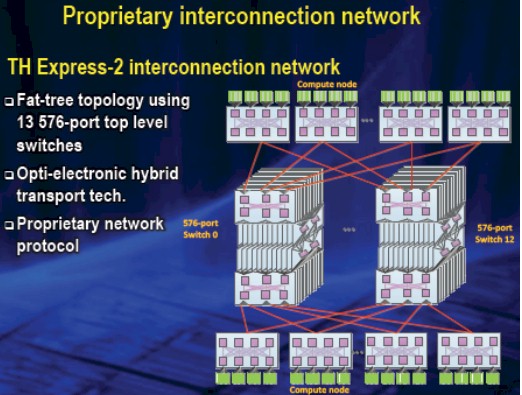
The TH Express-2 Arch interconnect created by NUDT
The Arch network has thirteen switches, each with 576 ports, at its top level, and that router chip, called the NRC and presumably short for network router chip, has a throughput of 2.76Tb/sec. The Arch network interface chip, called NIC of course, has a lot fewer pins (675 compared to 2,577 in the router) but is designed to have the same die size. This Arch NIC hooks into PCI-Express 2.0 slots on the compute nodes and it looks like there is one Arch port per node. These NIC ports hook into a passive electrical backplane and link local server nodes to each other. The thirteen 576-port switches are used to link groups of racks to each other in the fat tree setup. (Much like top-of-rack and end-of-row aggregation switches do in InfiniBand and Ethernet networks.) Presumably this is done with optical cables. The backplane is running at 10Gb/sec or 14Gb/sec, according to the presentation by Xiangke, and it is not clear if these are two different dialable bandwidths or if different parts of the backplane must run at these two different speeds.
Dongarra said that a broadcast MPI operation was able to run at 6.36GB/sec on the Arch interconnect with a latency of around 9 microseconds with a 1KB data packet across 12,000 of the nodes in Tianhe-2A system. Arch is said to be using a proprietary protocol, but I would bet it is a hodge-podge of different technologies and very likely a superset of InfiniBand. But that is just a hunch, and there are people much more qualified than this system hack to make better guesses.
The whole shebang has 125 compute racks and the thirteen Arch switch racks for a total of 138 racks, plus another 24 racks for storage (12.4PB in size) if you want to count that in the system. It runs the Kylin variant of Linux created by NUDT for the Chinese military as well as the H2FS file system. This beast consumes 17.4MW under load, and the closed-coupled, chilled water cooling system is designed to handle 24MW and - as it turns out - will warm up the water supply in Guangzhou. ®
