This article is more than 1 year old
Nvidia Tesla bigwig: Why you REALLY won't need x86 chips soon
Find out where Intel, AMD, ARM stand in GPU giant's roadmap
What's the difference between Tesla and Tegra?
TPM: For the HPC community, what will be the practical difference between Tegra and Tesla? What is to keep supercomputer shops from trying to build Tegra supercomputers out of those future Parker chips, or even Logan?
Scott: Tegra will never have a good network interface because it doesn't need one, and Tegra will not have the same amount of memory or bandwidth into the memory subsystem that Tesla has. At some point, you might have stacked memory in Tegra, like we are planning to do with the "Volta" Tesla chips, but it will be much smaller.
Tesla will never have high enough volume to justify the bulk of the engineering work that it takes to do a full solution. But it will have enough volume to justify the incremental engineering work that is necessary to take the consumer parts and make supercomputers.
TPM: How beefy will you get those Denver cores used in the Tesla products? Will it be enough to get rid of the X86 entirely?
Scott: That's the goal.
In terms of what you can do with it, there is really no difference between an ARM ISA and an X86 ISA. The ARM ISA is a little cleaner in terms of RISC, but an X86 processor is really just a RISC processor with this wrapper around it that converts X86 into a RISC ISA. I am very happy that most of the world thinks that ARM provides a great efficiency advantage over X86. The truth is, it really doesn't. It is a small second-order effect. The reality is, you squint and there is no power advantage to ARM.
The advantages that are important is that ARM is open, ARM is much higher volume, many more people are using it, and there is a lot of opportunity and ability to innovate. Historically speaking, that tends to win. It is the classic Innovator's Dilemma. I expect for ARM to do to Intel what Intel did to RISC and mainframes. You can't say for sure that it will happen, but again, volume (which means you can get by with lower margins) and openness and lots of people innovating should win.
TPM: Can you plunk a future InfiniBand port onto the Tesla package as well? Is that desirable? Can you put a ConnectX adapter or a whole switch, or a piece of a distributed switch like Calxeda is doing with its ARM server chips, down there?
Scott: You certainly could.
I think you get a lot of benefit from just doing the NICs. There are some pros and cons to trying to integrate the router as well, and it has to do with the ability to build different strengths of networks. It is easier to build fat or skinny networks this way if the ratio of processor to router silicon is not baked in. You also get pass-through traffic then, and you are using processor pins to route packets that are coming into the processor, and then out again, but are not terminating or sourcing at the processor. You are burning pins on your processor, which is fine if you always know what your configuration is going to be.
I am not going to tell you precisely what we are going to do, but it is a story of integration. We are looking out, later on in this decade, at a world where the third party HPC network ecosystem may go away.
If you look at the current Top 500, you have a bunch of Ethernet systems that are all at the bottom of the list and they have crappy efficiency, even on Linpack. Of the credible HPC systems, you have InfiniBand and custom networks from Cray, SGI, IBM, and a few others. Looking at that landscape going forward, QLogic is off the table and Cray's network is off the table because Intel has that and Cray is getting out of networks. BlueGene is off the table, from everything I understand, and there is no future BlueGene roadmap. The Tofu network on the big K machine from Fujitsu doesn't really have a commercial future. SGI is currently doing a custom network, but I don't know how long they will be able to continue to do that.
So what is left? It is Mellanox. And what does Mellanox do? Basically, it hooks up Xeon servers into clusters. And if Intel goes to a proprietary integrated network fabric, that doesn't mean that Mellanox's days are numbered – I don't want to give people the wrong impression here – but there is certainly a threat.
TPM: That's how I see it, too. And have said as much. Intel is not just buying up Fulcrum Microsystems, QLogic, and the Cray interconnects as defensive maneuvers to keep them out of enemy hands, but because it wants to build something and drive it down into the chips and into the switch ASICs that it clearly wants to sell to hit its 2016 target of $20bn in sales for the Data Center and Connected Systems group.
(I didn't think of it at the time during this interview, but maybe Nvidia should buy Mellanox and get it over with, keeping it in neutral territory?)
Scott: We are looking at a landscape where there may not be good third party networks available to interconnect GPU. We are also looking at selling processors, not just being an accelerator to other processors, so we need a network story.
TPM: Something like the Echelon development project you did for DARPA? That looked an awful lot like the Cray "Aries" interconnect in there.
Scott: The Echelon plan was to have an integrated NIC and a lot of bandwidth coming off the processor supporting a global address space across the machine – native loads and stores everywhere, and all of the synchronization that works between cores on a chip works seamlessly between cores on different chips. So you have got this very tightly integrated network fabric. And yes, our vision is a dragonfly network, same as Aries. The details are different, but there is a dragonfly topology.
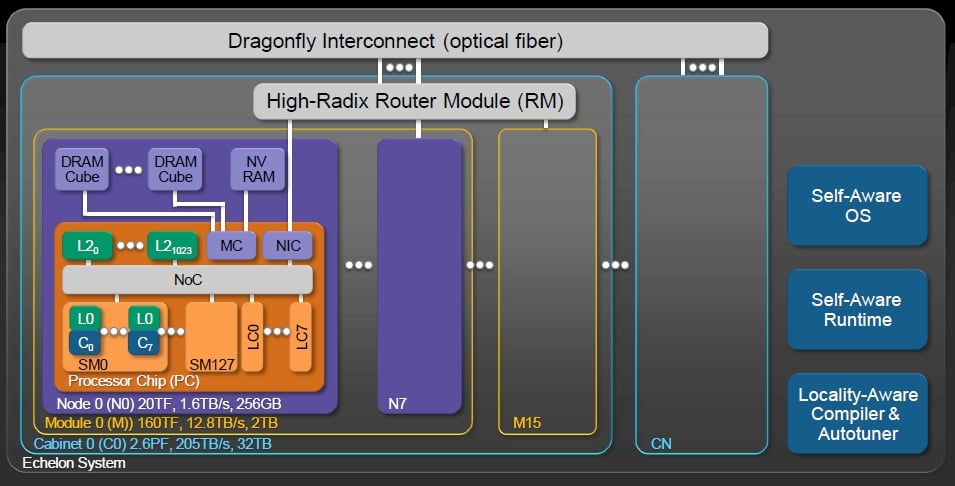
Block diagram of Nvidia's Echelon exascale system (click to enlarge)
TPM: I keep coming back to this, but do you have to do this yourself or pray that someone else figures it out?
Scott: That's a great question. At this point, we are just starting to think hard about this. When I was working at Cray, I was working with Bill Dally of Stanford University on Aries, and we are both here at Nvidia. There were two architects of the Aries router, myself and Mike Parker, who is now a senior research scientist at Nvidia. We clearly have the ability.
The question is, what do we do about it? It is not something we have figured out completely. We have ideas, and it is not something we are talking about, but we will make sure that there are good network solutions for future processors and you can imagine that there will be tighter coupling to the processor. We are talking to potential partners, too, since we really don't have any aspirations to be a standalone systems company.
TPM: And yet, Nvidia just announced the Visual Computing Appliance, so I don't necessarily buy that. (laughs)
Scott: Well, that's a specific appliance. . . .
TPM: But seriously. Sometimes you don't have the choice. Look at the choice that Cisco Systems faced when all of the server vendors started snapping up networking companies to expand their TAM and because they saw convergence and network virtualization coming. Cisco could either leverage its networking business to come into servers or lose market share. So there may come a day, because the world is a tough place, when the world may say to Nvidia that it can be an HPC systems company or not be invited to the party.
The trick will be to make whatever you do up there applicable to enterprise computing and hyperscale cloud operators like Facebook and Google. Don't pull an IBM and create BlueGene/Q and then not realize that it could be a killer microserver for running Hadoop jobs with a big price cut and some re-engineering so it fits in standard racks - or, I guess, Open Compute racks. (Laughter)
Scott: I would be delighted if the stuff that we are creating for HPC will be useful for general purpose data centers. We definitely think about such things. And from a networking perspective, a lot of things that are good for HPC are also good for scale-out data centers.
The systems that Google, Amazon, Facebook, and others are fielding are bigger than HPC supercomputers. And as they get rid of disks and start trying to run everything in memory, all of a sudden the network latency is starting to matter in a way that it didn't. They care about global congestion and communication, with jobs like MapReduce, and the amount of bandwidth per node is small compared to HPC.
But if you build a network right, it is sliced anyway. Both networks will have good global congestion control, good separation for different types of jobs, and good global adaptive routing – all with low latency. ®
