This article is more than 1 year old
GE puts new Nvidia tech through its paces, ponders HPC future
Hybrid CPU-GPU chips plus RDMA and PCI-Express make for screamin' iron
Not bad, not bad at all – but wait, there's more
This is a big improvement in terms of lower latency and higher throughput, obviously. And it would also seem to indicate that Intel will need to come up with something akin to PhiDirect to offer similar capabilities for its Xeon Phi parallel x86 coprocessor, and indeed, AMD would have to do the same for any FirePro graphics cards it wants to peddle as compute engines in hybrid systems if it wants to squeeze performance and get the CPU out of the memory loop.
RDMA with the GPUDirect feature and PCI-Express switching is not just for mil-spec gear providers such as GE, of course. Server makers have already come up with systems that use PCI-Express switches to gang up multiple GPUs to CPUs to get the ratio of GPU compute to CPU compute more in whack, and to actually enable the GPUs to do calculations according to their inherent capability.
This is a big step from the early days, explained Franklin, when a ceepie-geepie node looked something like this:

Before GPUDirect, each CPU managed a GPU and spent most of its time starting CUDA kernels
The typical node had two CPUs, each with their own main memory block and their own GPU hanging off it; an I/O endpoint hung off the PCI-Express bus that linked the GPUs to the CPUs and both to the other nodes in a parallel cluster. You had to go through the CPU memory stack to move data into and out of the GPU, and between that memory management job and the launching of CUDA kernels on the GPU, the CPUs were so saturated that they had trouble actually running their applications.
You certainly could not hang more multiple GPUs off a single CPU because it would have choked to death. Still, as you can see from the single-precision and double-precision matrix multiplication benchmark results in a typical setup using Xeon E5 and Kepler K20X GPUs, the gigaflops-per-watt of the combination was much better than what you could get from the CPUs alone.
Enter the PCI-Express switch and RDMA with GPUDirect memory addressing. Now, you can hang four GPUs off of a single processor, and according to Franklin, only a fraction of a core is busy launching CUDA kernels as applications run, and the memory overhead is much diminished. And now you can get a significant improvement in gigaflops-per-watt coming out of the resulting system.
But don't stop there. You can daisy-chain PCI-Express switches and push it out like this:
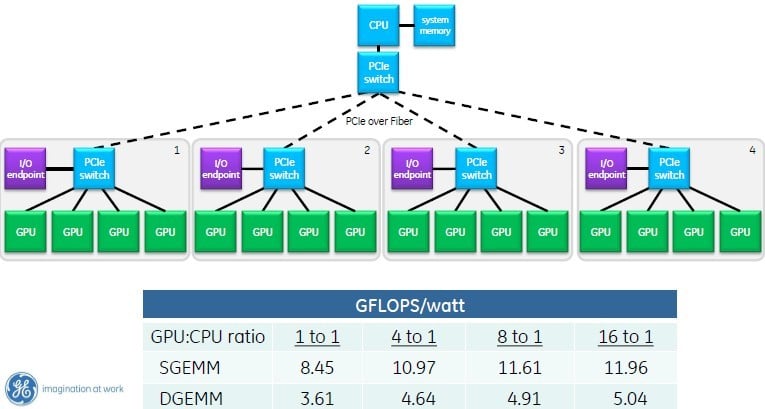
With GPUDirect, RDMA, and nested PCI switches, you can hang up to sixteen GPUs off one CPU (click to enlarge)
The current crop of PCI-Express 3.0 switches top out at 96 lanes of traffic, and you can drive five x16 slots on them. Or you can drive four and leave some lanes to talk upstream in the nested arrangement that Franklin cooked up in the chart above.
Now, instead of getting 8.45 gigaflops-per-watt single precision and 3.61 gigaflops-per-watt double precision, you can push that up considerably – try 41.5 per cent more power efficiency at single precision and by 39.6 per cent at double precision. (These figures include the heat generated by the PCI switches and also take into account the latencies added by the PCI networks.)
So here is the net effect this all has, by Franklin's math, on the cost of the ceepie-geepie computing complex in a 10-petaflops parallel supercomputer with various CPU-to-GPU ratios:
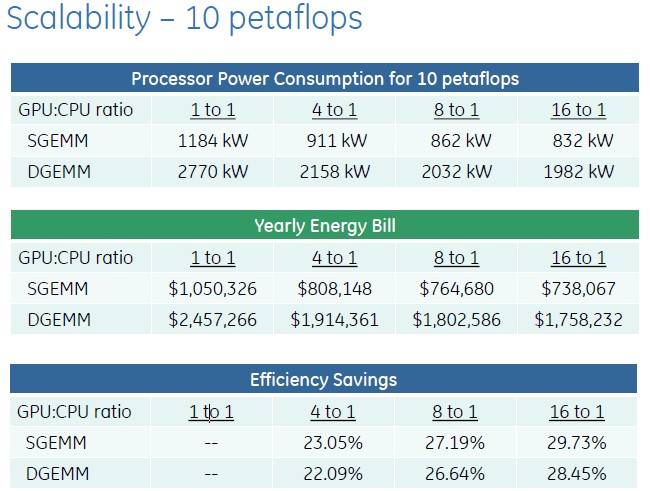
Scaling up the CPU and GPU compute using PCI switching saves energy and money
Franklin called this a "typical machine," which got some chuckles from the peanut gallery of El Reg hacks and their dubious associates seated in the front row.
There's plenty of data to play with in this table, and this just includes the electricity consumed by the CPU, GPU, and PCI-Express switching, if the latter is present, and the cost of that electricity at the national US average of 10 cents per kilowatt-hour for industrial companies (rather than consumers).
Obviously, with fewer CPUs driving the GPUs, you can burn a lot less juice as well as allocate more of the money for GPUs than CPUs. By going with a 16:1 GPU-CPU ratio, Franklin calculates that you can save close to 30 per cent on the electric bill on a 10-petaflops super. Those energy savings can be plowed back into software development or incremental scaling of the cluster. (We know; every one of us would buy more hardware with the savings.)
