This article is more than 1 year old
Nvidia launches not one but two Kepler2 GPU coprocessors
Uncloaks Tesla K20, K20X extreme oomphers for servers, workstations
SC12 The wait for the "Kepler2" GPU coprocessors based on the company's GK100 GPUs is over. That's the good news.
The bad news is that you may have to hurt someone – or call in a favor at Nvidia – to get your hands on one, because so many people are going to be looking for one to goose their number-crunching. And you'll have to get in line behind Cray, which is building the "Titan" and "Blue Waters" 20-petafloppers using the devices.
Nvidia launched its Tesla K10 GPU coprocessor, which has a pair of "Kepler1" GK104 GPUs on a card, back in June at the International Super Computing conference in Germany. Having already talked up some of the performance specs of the K20 coprocessors back in September, Nvidia was expected to do the final rollout of the K20s at the SC12 supercomputing conference in Salt Lake City this week, revealing the feeds and speeds of the devices.
Having already split the product line in two with the K10 aimed at single-precision workloads, and the K20 aimed at double-precision jobs, what was perhaps not expected was that Nvidia would split the K20 line further with a high-end box aimed only at servers.
That's the K20X, an extreme edition with more cores and higher clocks that delivers more number-crunching oomph.
By splitting the Kepler line in two with the GK104 and GK110, Nvidia is conceding that its GPUs for graphics processing on PCs and workstations are not going to cut it on the workstation and supercomputing cluster workloads, where double precision is necessary. And the GK110 is a monster of a chip, one of the most complicated chips Nvidia – or anyone else, for that matter – has ever done. Think of it as the kind of GPU that might appear in your PC years from now.
Nvidia also split the Tesla K20 line to be forward-thinking in a different way. "More and more applications are starting to use mixed precision," Sumit Gupta, senior director of the Tesla business unit at Nvidia, tells El Reg.
So if you go with the higher-end K20 or K20X GPUs, you can go either SP or DP and hedge your bets. The K20 and K20X let companies, supercomputer labs, and cloud suppliers not sure what applications they might run, build machines that can do either – and do it well. If you know you'll never need double precision, you'll be able to go with the Tesla K10s and presumably pay a little bit less per SP flops.
The GK104 versus the GK110
The GK104 weighs in at 3.54 billion transistors, and bundles 192 single-precision CUDA cores into what Nvidia calls a streaming multiprocessor extreme (SMX) bundle.
The GK104 has eight SMX units for a total of 1,536 cores. Each SM unit has 64KB of L1 cache and 768KB of L2 cache added for the SM to share. Unlike the predecessor "Fermi" GPUs, the Kepler1 GK104 chip has 48KB of read-only cache memory tied to the texture units. On the Tesla K10 card, all of the 1,536 cores are fired up, and there are two GK104s on the PCI-Express card, each with 4GB of GDDR5 graphics memory and 160GB/sec of memory bandwidth off the card.
The Tesla K10 card has a piddling 190 gigaflops of double-precision math, but a whopping 4.58 teraflops of single-precision. For weather modeling, life sciences, seismic processing, signal processing, and other workloads that don't care a bit about DP floating point, this GPU coprocessor is exactly what the scientist ordered.
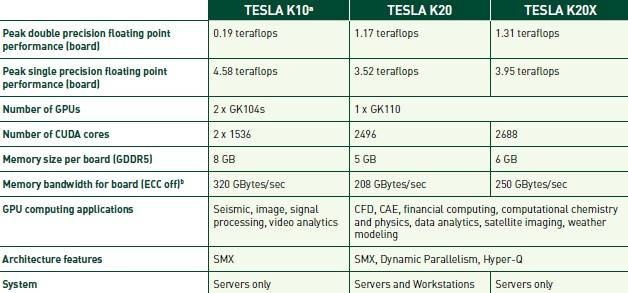
Salient characteristics of Tesla K10 and K20 GPU coprocessors
The GK110 chip is not just two of these GK104 chips on a single die. The Kepler2 GPU is based on a different SMX unit. It has 192 CUDA cores per SMX, just like the GK104, but adds 64 double-precision floating point units as well as doubling up the L2 cache across the SMX to 1.5MB and doubling up the bandwidth across that L2 cache.
The GK110 chip has a staggering 7.1 billion transistors and sports fifteen of these SMX units, as El Reg detailed back in May, but the Tesla K20 card has a GK110 with only thirteen working SMX units, and the top-end Tesla K20X card has a chip with fourteen SMX units.
At some point in the future, when yields improve on the GK110 chips, there will no doubt be K20 and K20X cards with all of the SMX units fired up, and possibly with slightly higher clock speeds, as well – perhaps a year from now at the SC13 show.

The Tesla K20 GPU coprocessor card
Nvidia was cagey about the feeds and speeds of the K20 in May at its GPU Technical Conference, but those stats are a lot lower than the speeds on the Tesla K10s – as we expected. The K20 has 2,496 CUDA cores plus another 832 double-precision cores, all running at 706MHz. The 5GB of GDDR5 memory runs at 2.6GHz and delivers 208GB/sec of bandwidth.
The K20X cranks the CUDA core count up to 2,688, the DP core count up to 896, and the clock speed up to 732MHz across those cores. The K20X has 6GB of GDDR5 memory, and the card has 250GB/sec of bandwidth out of that memory. The top-end K20X delivers 1.31 teraflops of DP floating point crunching and 3.95 teraflops SP performance. It is this GPU, as it turns out, that both the Titan and Blue Waters supercomputers will be using.
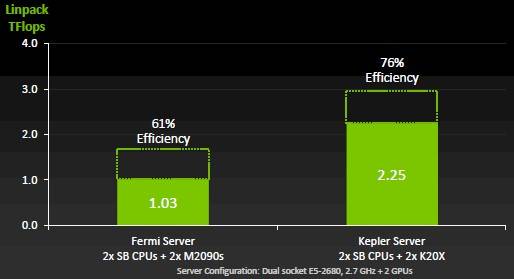
The K20 is more efficient than the M2090
The K20 and K20X GPU coprocessors support Hyper-Q and dynamic parallelism, two key features that make parallel supercomputers more efficient when they run hybrid CPU-GPU applications.
These features are not supported on the K10 GPU coprocessors, and by the way – according to Nvidia – these features are not ones that the Linpack Fortran vector and matrix math benchmark make use of. Hyper-Q allows for up to 32 MPI tasks to be dispatched to the GPU at a time, compared to only one at a time for the prior Fermi GPUs, while dynamic parallelism allows for the GPU to spawn its own work and not go back and forth to the CPU so much, thereby boosting performance.
The K20 and K20X GPUs also support ECC memory scrubbing on the GDDR5 memory, and those bandwidth numbers cited above are based on having it turned off. If you turn it on, then 12.5 per cent of the memory will be used to store ECC bits. Presumably this also cuts down on bandwidth into and out of the GDDR5 memory.
