This article is more than 1 year old
UV 2: RETURN of the 'Big Brain'. This time, it's affordable
Hefty loads bursting out of your box? Try this
Counting up the cores and threads
The UV 1000 could span as much as 2,560 cores and 5,120 threads using the ten-core E7 chips, but the Linux kernel tops out at 4,096 threads at the moment, so that was as far as the thread count could be pushed. That limit has not changed in the Linux kernel, so a full-on 4,096 core UV 2000, if SGI ever built one, would top out at 4,096 cores and would not be able to take advantage of HyperThreading, which provides two virtual threads per core.
Bill Mannel, vice president of product marketing at SGI, tells El Reg that the Linux kernel usually gets all of the features to support the future NUMAlink interconnect between 9 and 12 months ahead of launch, so the current Linux distros already can run on the new machine. Red hat Enterprise Server 6 and SUSE Linux Enterprise Server 11 are supported right out of the box (er, right form the download), and presumably SGI will soon offer certification on Windows Server 2008 R2 and is working on support for the forthcoming Windows Server 2012, due later this year or early next. SGI has been making a big deal in the past year that it can push Windows Server 2008 R2 to its limit of 256 cores without breaking a sweat. It will be interesting to see if Microsoft and SGI will patch Windows to do a better job scaling across UV 2000s and at least try to compete with Linux on this machine.
The UV 2000 has basically twice the cores and supports four times the global shared memory as the UV 1000 it replaces, and the local read latency on a node is 80 nanoseconds on the UV 2000 compared to 130 nanoseconds on the UV 1000. The full read latency from distant nodes is under 1 microsecond for both machines – you have more than double the bandwidth, but you also have four times the nodes to span. The UV 1000 could deliver around 6 teraflops per rack, and the UV 2000 delivers 11 teraflops. (This assumes top bin parts in both cases, presumably.) The machine has an aggregate of 4TB/sec of aggregate I/O bandwidth across its PCI-Express 3.0 slots, too.
Both the UV 1000 and UV 2000 machines can scale out beyond their 128 and 256 node limits (that's the production scalability on the machine). What you do is use InfiniBand to link a bunch of UV blades together in a fat tree configuration, and then use the NUMAlink interconnect to lash those clusters together into a larger cluster that has globally addressable memory but not tightly coupled shared memory. You can do a maximum of 16,384 sockets across 128 racks with such a monster configuration, which would give you around 1.41 petaflops of number-crunching power and 8PB of addressable memory.
Price point
What has SGI excited with the UV 2000 is not just the increased processing and memory scalability, but the lower cost of the machines compared to the UV 1000. A base UV 1000 node with two eight-core Xeon E7s and 32GB of memory cost $50,000, but Mannel says that SGI can put a UV 2000 node with two Xeon E5-4600s and 32GB into the field for $30,000. That's a 40 per cent price cut, and that will go a long way toward expanding the addressable market of the UV machines if all of the other parts of the machine (extra routers and do on) don't add too much to the cost of a configured system.
SGI will be stressing the memory bandwidth and capacity of the UV 2000 compared to big SMP servers and to flash memory arrays. SGI says that a ProLiant DL980 eight-socket from Hewlett-Packard with 80 cores (Xeon E7) running at 2.26GHz and with 1TB of main memory will cost $93,000 and get you around 7.5 gigaflops for every thousand bucks you spend on the machine. A 128-core UV 2000 with 2.6GHz Xeon E5-4600s and 1TB of memory will cost you $98,000, but you will get over 14 gigaflops for every grand you spend. As for the comparison with flash, SGI says that two Dell rack servers with 1.2TB of high-end Fusion-io flash memory will give you a read/write bandwidth in the range of 2.5GB/sec to 3GB/sec at a latency of between 15 and 47 microseconds, but if you instead use four UV 2000 node enclosures (that's eight CPU sockets) equipped with 1TB of memory, you get a read/write bandwidth of around 236GB/sec and a latency of between 100 to 500 nanoseconds. That's 100 times the performance and 35 times better bang for the buck for the UV 2000 nodes, says Mannel. That is also another way of saying that the UV 2000 nodes are three times as expensive, but you'd expect that when comparing main memory and flash devices.
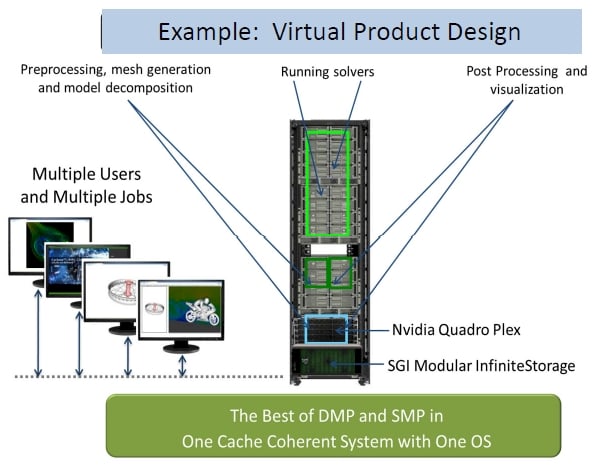
The other sales tack that SGI will be making is to convince customers that they can do multiple jobs inside of a UV 2000 machine, supporting multiple users doing related work.
Applied Micro X-Gene ARM block diagram (click to enlarge)
For instance, you can put a block of Nvidia Quadro graphics cards in a chassis in the UV 2000 rack along with some Infinite Storage arrays and the UV 2000 enclosures and create a machine that can do all aspects of virtual product design inside the complex. This includes preprocessing, mesh generation, and model decomposition for the design, running solver programs to do the design, and then post processing and visualization to actually see the design. SGI is allowing customers to plug Intel's forthcoming "Knights Corner" MIC x86 coprocessors into the chassis as well as the Tesla family of GPU coprocessors as well, but has not gone so far as to link one Xeon socket to one GPU like other system designs are doing.
SGI is already shipping one UV 2000 system to a customer in the United States (a "well known auto company") and is working on manufacturing a couple more that will soon ship to customers in Europe, including the UK Computational Cosmology Consortium at Cambridge University where physicist Stephen Hawking gets his paycheck.
In addition to the UV 2000 high-end machine, SGI is also kicking out a four-socket, 2U rack server called the UV 20 that is intended to be a development machine for the UV 2000. ®
