This article is more than 1 year old
Nvidia's Kepler pushes parallelism up to eleven
Hyper-Q and Dynamic Parallelism make GPUs sweat
Get to work, you lazy core
No matter how Nvidia is doing it, the important thing is that the CUDA cores are not going to be sitting around tapping their feet, waiting for MPI to send them work from the CPU. While seismic workloads can already stress out a GPU dispatching one MPI task to the GPU, there are many workloads that can submit four or eight MPI tasks, says Gupta, and on the current Fermi GPU coprocessors, the efficiency for sparse matrices or finite element analysis can look "really bad".
On the VGEMM double precision matrix multiply portion of the Linpack Fortran benchmark test, Hyper-Q helps significantly. The VGEMM to peak ration on the Fermi GPUs was at best around 65 per cent of peak theoretical performance, while on the Kepler GPUs it is in the range of 80 to 85 per cent.
On typical workloads, customers were seeing GPU utilization on the Fermis in the range of 25 to 50 per cent, but now customers can expect – thanks to Hyper-Q and depending of course on their code – efficiencies of between 70 and 90 per cent for any particular time slice.
Not only is the Kepler GPU better at juggling work that the CPU offloads to it than the Fermi chip was, but with the Dynamic Parallelism feature of the chip, the GPU can launch work for itself as it deals with nested loops, recursion, and nested calls to libraries.
"The GPU has become more autonomous," says Gupta, "and this makes the GPU programing a lot easier. If you have to go back and forth to the CPU all the time to run routines, you lose many of the advantages of using a GPU in the first place." So Dynamic Parallelism gets rid of that.
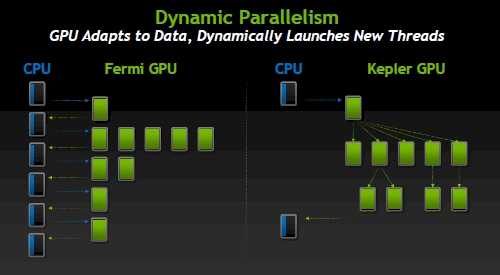
Nvidia's Dynamic Parallelism for Kepler GPUs
The idea behind Dynamic Parallelism is not just to make the GPU more autonomous for its own sake, but to allow for the granularity of calculations to reflect the density of the data that is being generated for a simulation. While this may be a a little tough to grasp conceptually, one picture makes it clear why Dynamic Parallelism is a very powerful addition to the GPU toolkit:
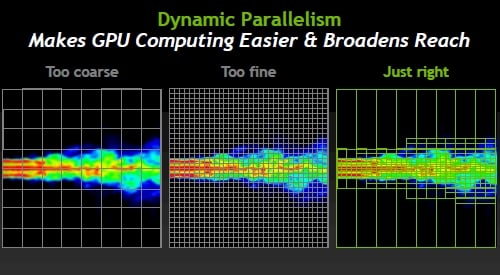
Variable granularity is what Dynamic Parallelism does for GPUs
The driving force behind Dynamic Parallelism in the Kepler GPUs is to allow for regions of simulation to be dynamically adjusted. If you do it too coarsely, your simulation yields crap results, and if you do it too finely, you get good results but it takes forever because you are doing calculations on regions of virtual space in the simulation where nothing interesting is happening.
The idea is to do coarser calculations where space is boring and finer calculations where lots of stuff is going on, and more importantly, to allow the GPU to make decisions about the granularity of calculations on the fly. The GPU reacts to the data, launching new threads to do finer-grained calculations where required.
Add it all up, and Gupta says that the Kepler GPUs will appeal to a much broader set of calculation and simulation workloads. "All of these people who were sitting on the fence will now move to GPUs," declares Gupta.

Nvidia's future Kepler-based Tesla
K20 GPU coprocessor
Well, not so fast. They will once they can get their hands on some Tesla K20 coprocessors using the Kepler2 or GK110 GPUs. These will not ship until the fourth quarter of this year, and these will offer three times the double precision performance of the Fermi GPUs – that's just under 2 teraflops with two GK110 GPUs on a card and the Hyper-Q and Dynamic Parallelism features activated.
In the meantime, Nvidia is packaging up the Tesla K10 coprocessor card for servers, which puts two of the Kepler1 or GX104 GPUs on a single card and offers three times the single-precision math oomph of a top-end Tesla M2090 card using the full-on Fermi GPU.

Nvidia's Tesla K10 GPU coprocessor for single-precision math (click to enlarge)
The Tesla K10 and K20 GPU coprocessors slide into PCI-Express 3.0 slots, which means that at this point in the server cycle, they only work with Intel's Xeon E5 family of "Sandy Bridge" processors for two-socket and four-socket servers. No other server chip is supporting PCI-Express 3.0 slots at this time.
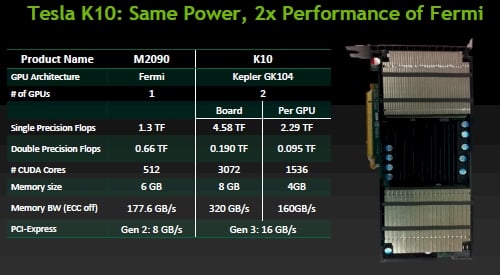
Old Tesla M2090 versus new Tesla K10
As you can see, the Tesla K10 can't do much in terms of double-precision math, but at 4.58 teraflops per card and 320GB/sec of memory bandwidth (that's with ECC turned off on the GDDR5 memory) feeding those 3,072 cores on the board from the two ranks of 4GB memory (one for each GPU) and 16GB/sec of bandwidth out to the PCI bus, there are plenty of customers doing seismic, signal, image, and life sciences workloads that only use single-precision math anyway. So the Telsa K10s will be fine.
Those doing finite element analysis, computational fluid dynamics, various physics simulations, and financial calculations and simulations that are dependent on double-precision floating point math will have to wait for the Tesla K20 cards using the Kepler2 GPUs. Perhaps not patiently, but with AMD not really doing much with its FireStream GPU coprocessors and Intel not shipping its MIC parallel X86 coprocessors, waiting is the best and pretty much the only option. ®
