This article is more than 1 year old
Fujitsu saddles up its own Hadoop distro
Forget HDFS
Japanese IT conglomerate Fujitsu is throwing its own elephant into the ring with a mashup of Fujitsu software with components of the Apache Hadoop big data muncher, which it says is better than just using the open-source code all by its lonesome.
Like many Hadoop users, customers using Fujitsu's mainframe, Sparc, and x86 iron complain about the crankiness and limitations of the Hadoop Distributed File System (HDFS), and so the company has grabbed the Apache Hadoop 1.0 stack that was announced in January and given HDFS the boot. Or rather... not.
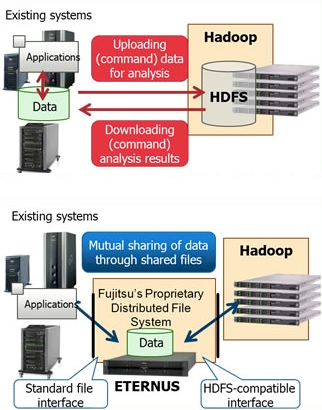
The problem, according to Fujitsu, is that enterprise systems and Hadoop systems store their data in different formats and in distinct systems and you end up having to upload data from those enterprise systems to a Hadoop cluster, chew on them, and then download the reduced data back into enterprise systems.
Plain Hadoop on top, juiced Fujitsu Hadoop on bottom
With the Interstage Big Data Parallel Processing Server V1.0 takes the Hadoop MapReduce algorithm and marries it to a proprietary distributed file system cooked up by Fujitsu that the enterprise systems and the Hadoop cluster can use as peers. This file system runs on the hosts and makes use of Fujitsu's Eternus disk arrays and has a standard Linux interface for those enterprise systems and an HDFS-compatible interface for the Hadoop cluster to use it.
Fujitsu does not name this proprietary distributed file system, but it could be a variant of the Fujitsu Exabyte File System, announced last year and targeted at the company's supercomputer customers. (FEFS is itself a variant of the open-source Lustre file system.)
The other innovation that Fujitsu is tossing into its Interstage Hadoop distro is the ability to cluster the Hadoop master node – the controller that tells what server nodes to chew on what data and a single point of failure as well as a performance bottleneck for Hadoop clusters – for high availability.
The big plus is that both Hadoop and enterprise systems can chew on the data residing on the Eternus arrays, and this speeds up Hadoop jobs considerably because you are not waiting for enterprise data to be uploaded into the Hadoop cluster. This presumes that you don't have other external data that you also want to chuck into the MapReduce pot, and that is not necessarily a valid assumption for a lot of companies that are doing big data these days.
Interstage Big Data Parallel Processing Server V1.0 will begin shipping at the end of April. It will cost ¥600,000 ($7,465) per server processor for a license. Fujitsu says that prices outside of Japan may vary. ®
