This article is more than 1 year old
Teradata grabs Hortonworks by trunk
An elephant line from Hadoop to data warehouse
Teradata doesn't want to be an elephant, it wants to ride them.
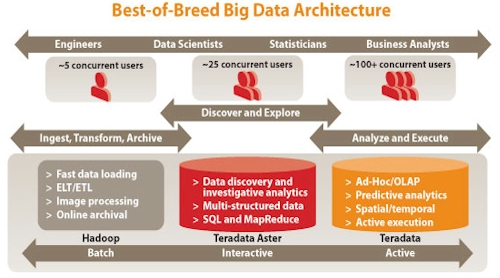
The data warehousing pioneer has been loath to create its own distribution of the Hadoop data muncher – most likely because of the shortage of deep Hadoop skills out there – and has been partnering to lash the open source MapReduce program and file system to its Aster Data SQL-MapReduce hybrid and its Teradata data warehouse appliances.
A year and a half ago, Teradata partnered with Cloudera, the upstart company founded by several of the key people at Yahoo!, where Hadoop was invented, to provide a pipe linking Hadoop clusters to Teradata warehouses.
Since that time, a number of other distributions of the Hadoop stack have been launched to compete with Cloudera's CDH3, including MapR Technologies' M3 open source and M5 open-core, which is resold by EMC's Greenplum data warehousing division as MR Enterprise Edition, and the Hortonworks Data Platform. Hortonworks is a later spinout of techies from Yahoo! who worked on more recent projects at the search engine and media company. Neither Cloudera nor MapR are committed to open sourcing all their goodies, but Hortonworks is. It is not clear how important this is to Teradata or its customers.
Cloudera, Hortonworks, and Facebook are the big contributors to the Apache Hadoop project, which is written in Java, which implements the MapReduce data sifting technique with the Hadoop Distributed File System, and which is open sourced under an Apache license.
Teradata is no stranger to the MapReduce technique of sifting through data, and in fact it bought Aster Data in March 2011 for $263m precisely because it had implemented its own twist on MapReduce atop a distributed SQL database, called Aster Database, that can chew on structured or unstructured data in either column or row orientation.
Tasso Argyros, co-president at the Aster division of Teradata, tells El Reg that the MapReduce algorithms in the SQL-MapReduce database created by Aster are distinct from those in the Apache Hadoop stack. Apache Hadoop, says Argyros, is designed to take text data and application data (such as log files, clickstreams, and do on) and refine it in batch mode and have it make associations between bits of data.
This refined data can then be fed into a SQL-MapReduce machine, where the "golden nuggets" of information can be culled from the refined data, and then having found these nuggets, this data can be either immediately used for some effect or passed off to a data warehouse and mixed with operational data to help run the business.
"Hadoop is great for batch processing and data transformation," explains Argyros. "With Aster Data, our MapReduce is used more for iterative analytics."
An elephant line of data munching, from Hadoop to Aster Data to Teradata
The Cloudera deal from September 2010 provided a pipe from a Hadoop cluster into the Teradata data warehouses, while the Hortonworks partnership announced today is providing a pipe between Hadoop and Aster Data appliances.
Hortonworks and Teradata will do joint marketing and development, and are exploring ways to better integrate their respective software. This will specifically be done on Data Platform 1.0 from Hortonworks and Aster Database 5.0 from Teradata. Future engineering work could include running the HortonWorks and Aster Data programs on the same physical clusters, side-by-side, although this is not the way customers tend to do it today, according to Argyros.
Companies coping with unstructured data may want to run Hadoop on the cluster to refine their data and then Aster Database on it to do analytics that would take longer using Hadoop's MapReduce technique. As long as this work can be done in two-cycle fashion and the data can be accessed by the cluster nodes, this would be cheaper than having two separate clusters to run Data Platform and Aster Database.
The companies are also working on reference architectures to help customers use best practices as they build Hadoop and SQL-MapReduce clusters. Teradata has also become a reseller of the commercial Data Platform stack under the deal.
The financial terms of the partnership between Teradata and Hortonworks were not divulged. ®
