This article is more than 1 year old
Big Data in Context
Beyond the relational database
Big Data is an ‘umbrella’ term that is commonly used to refer to a number of advanced data storage, access and analytics technologies aimed at handling high volume and/or fast moving data in a variety of scenarios. These typically involve low signal-to-noise ratios, such as social media sentiment monitoring, or log file analysis, to mention just a couple. If you listen to the PR folks, it’s the next ‘big thing’ in IT, but does it really warrant the relatively high level of media attention and coverage it is currently receiving?
We wanted to gain practical insights into the context for some of the ideas and solutions often associated with the ‘Big Data’ phrase, and to test the extent to which they are actually reflected in current operational practices and future plans. And where better to go for a down-to-earth view than the Reg readership?
To this end, we ran a survey on The Register during November of 2011, which allowed 122 respondents to give us their feedback in this area - and thanks to all those that participated for their inputs and insight.
Given the number of vendors jumping onto the bandwagon, it’s hard to pin down where the Big Data discussion stops and starts, so the scope of the survey included both long-established data management approaches and some of the emergent technologies which are often (but not exclusively) associated with the Big Data label. These include scale-out storage architectures, distributed indexing and search tools, distributed analytics solutions as well as stream based processing technologies.
Looking at the results, the first and most obvious observation is that Relational Database Management Systems (RDBMSs) continue to rule the roost when it comes to data storage, management and analytics technologies
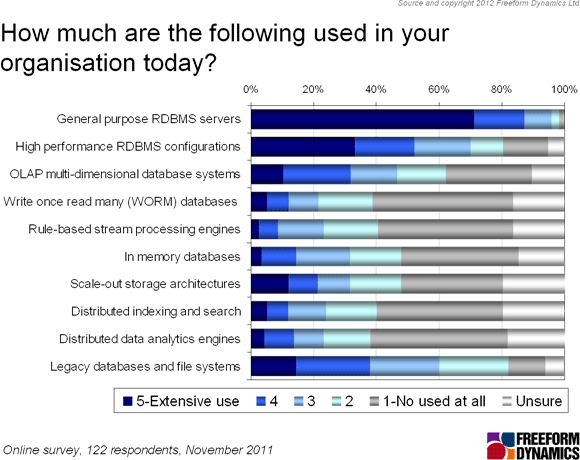 Figure 1
Figure 1
By comparison, the aforementioned ‘Big Data’-related solutions currently have a very small footprint, especially when we consider the ‘self-selecting’ nature of the sample, meaning early adopters are likely to be over-represented. The limited penetration we see is not surprising given that the surge in promotional activity is a relatively recent phenomenon, even if some of the technologies now labelled ‘Big Data’ have existed in niches for many years.
However, the increasing role of Big Data solutions in the mainstream over time does come through when we look at how the use of data management technologies might change over the next three years (Figure 2).
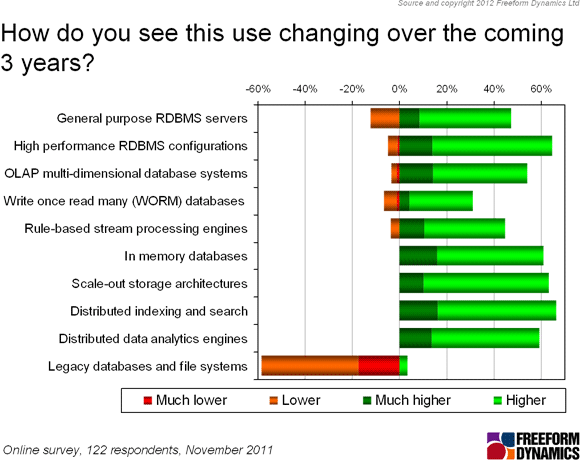 Figure 2
Figure 2
With the exception of legacy databases and file systems, which are clearly anticipated to be in decline, the overriding message from this chart is that all forms of modern data management and analytics solutions will be in greater demand in the short to medium term. This reflects the fact that Big Data technologies often allow new types of problem to be tackled - e.g. large, dirty and/or noisy data sets - but this doesn’t mean that more familiar problems go away. Indeed, while we haven’t shown it here, this latest survey confirmed what most of us know already, i.e. that data volumes are increasing across all record types while the thirst for actionable information and insights among business users continues to escalate.
Turning to practical implementation matters, the potential for adopting any new technology is generally constrained by the available levels of awareness, understanding and expertise available. Therefore, data management professionals will need the right skills and knowledge to exploit the full range of technology options effectively. With this in mind, the survey sought to gauge the current levels of familiarity (Figure 3) with a variety of solutions.
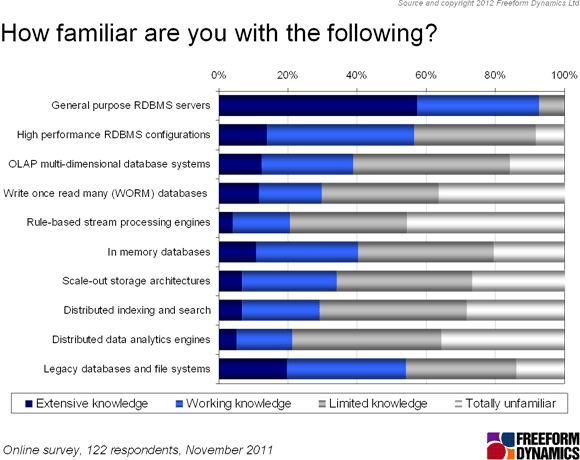 Figure 3
Figure 3
Comparison of future intent (as previously seen in Figure 2) with the current levels of technology familiarity (Figure 3) indicates the need for improving awareness, understanding and skills, particularly in the areas of: scale-out storage architectures, distributed indexing and search, along with distributed analytics engines. It is to be expected that knowledge levels will climb as organisations investigate and pilot Big Data flavoured solutions that pretty much all of the large established IT vendors, as well as a plethora of newcomers, are now starting to make available in some form or other.
However, as Big Data action develops, one message from the survey is very clear, namely the emergence of advanced storage, access and analytics solutions does not represent the end of the traditional RDBMS (Figure 4).
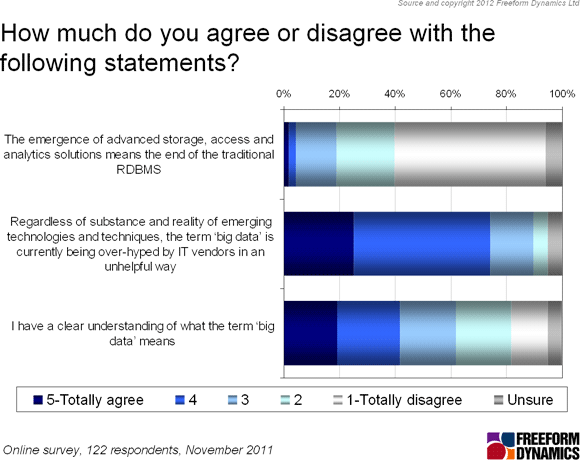 Figure 4
Figure 4
We can also see that as vendors fall over themselves to reposition anything and everything to with data management as ‘Big Data’, the hype monster is again rearing its ugly head. And given the confusion that comes with this, it is not surprising that around 40% of respondents have no clear understanding of what the term ‘Big Data’ means.
Once you strip away the hype terminology, though, it’s clear that a majority of respondents see that the technologies we asked about can bring benefits, both in terms of tackling existing problems and new approaches to meeting current as well as emerging business requirements (Figure 5).
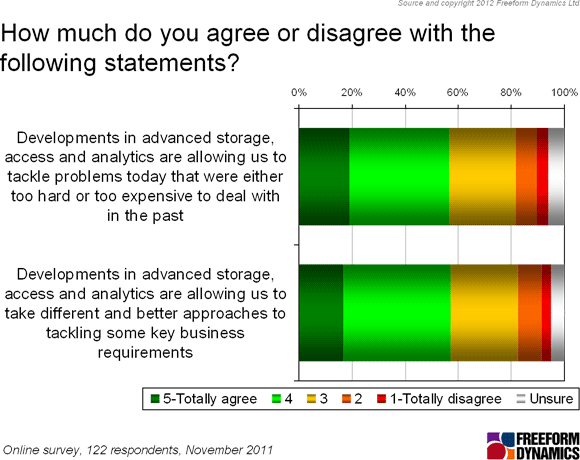 Figure 5
Figure 5
In a nutshell: ‘Big Data’ technologies have a lot to offer, but they’re not going to replace existing, modern database and analytics infrastructures. However, everybody would be better served if vendors toned down the hype and focused more on communicating what types of ‘Big Data’ solutions they have available, and which use cases those solutions can address. Otherwise, there’s a risk that the marketing fog ends up obscuring the real message, which in turn will inhibit adoption and delay the moment when companies can reap the business benefits of ‘Big Data’.
