This article is more than 1 year old
Disaster recovery blurs into high availability (or other way round?)
It's a virtualisation thing
Workshop IT managers use two terms when talking about systems availability. These are: High Availability or “HA”, for keeping systems running without any form of unplanned down time; and Disaster Recovery or “DR”, for ensuring that systems are rapidly returned to operation if they fail.
Some confusion has developed between these terms over the years.
Today, many vendors use HA and DR almost interchangeably. This is especially evident when they talk of applying the expanding range of virtualisation solutions to improve systems availability. It is almost the case today that the terms have become blurred to such a degree that it is worth asking the question, is there any difference between the two?
Following on from early consolidation of servers using virtualisation, organisations are beginning consider what advantages there might be in actively managing virtualised systems.
In addition, there is some interest in creating “private cloud solutions”. This attention, coupled with the hype surrounding external hosted and outsourced services, may help shape thoughts on these capabilities.
Another factor coming into play is the question of how virtualisation might help organisations to extend the systems to which they provide HA / DR capabilities. Until very recent times, the high cost and complexity of providing either HA or rapid DR capabilities has meant that only the most important of business services and applications operated in these fashions.
But now organisations must work out how to assess the cost of availability/continuity for an expanding range of applications, potentially by creating a business service catalogue that prioritises and costs such characteristics in service level agreements.
Human wrongs
Before considering if there are any real differences between systems offering HA or DR capabilities today, let us look at the causes of application delivery. The figure below is illuminating in many ways, showing that human generated failures are very well represented as the primary cause of service interruption.
Effective use of change management processes and tools, coupled with higher levels of “automation”, can help reduce the instances of human error considerably.
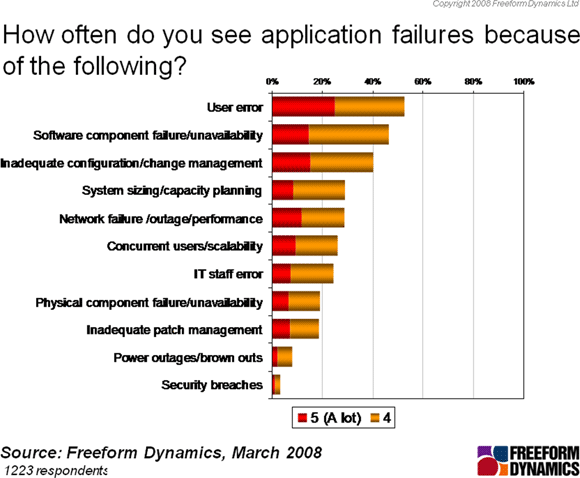
Genuine system problems, such as network failure, physical component failure or power outages, are much less likely to be at the heart of an interruption to service availability. The days when hardware failure was the usual problem to be fixed are behind us as reliability, availability and serviceability features have migrated into commodity servers.
We can look deeper into the question of whether HA and DR mean different things today than they did even in the recent past. Until recently, the term HA was applied only to systems that needed to function with strict limits on any interruption to service delivery, at least as perceived by the end users or customers of the service.
DR, on the other hand, was the phrase applied to the process of getting a service up and running again with users back working, following any form of systems / network failure or any other form of service interruption. In extreme circumstances, DR was also commonly applied to describe how to respond to the complete loss of a service or an entire system, or potentially recuperating from the loss of a building, computer room or data centre.
Today, it is clear that the accepted usage and understanding of these terms has changed significantly. This is most notable when considering the language commonly used around virtual servers. It is quite common to see the two terms used almost interchangeably with little differentiation. Some vendors are prone to describe the now relatively well established ability to spin up a new virtual machine rapidly following a service degradation or interruption as HA.
Assume the recovery position
This usage is not particularly accurate, as it amounts to just fast, and potentially quite simple to enact, recovery from failure, better known as DR. In fairness it should be mentioned that whilst some vendors use HA in this way, others prefer to describe such scenarios as a natural extension of DR.
As mentioned above, a major use of the term DR has been to describe what happens when something big happens to a system that threatens the ability to run a range of services in that location. Expanding DR to include the recovery capabilities of single virtual machines or VMs running on a physical system is not a big stretch in usage. It is now possible to implement genuine HA with virtual systems, but this needs additional software management tools.
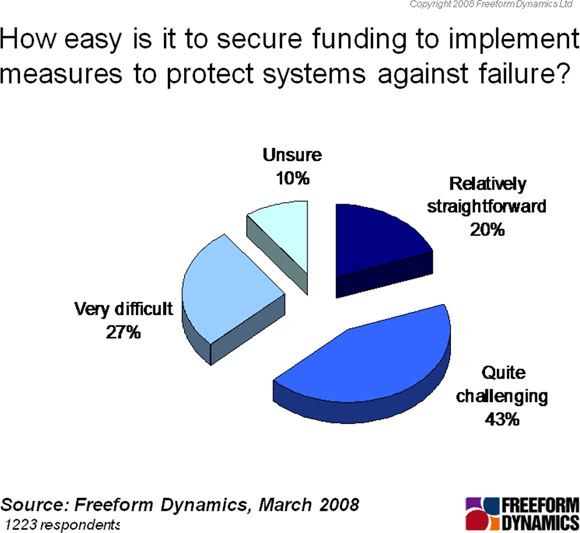
It remains to be seen if the distinction between the two terms will remain meaningful in the coming years, as virtualised systems and associated management tools become ever more widely deployed. In some ways, the distinction between HA and DR may even prove to be helpful to IT managers, as the chart above highlights just how difficult it has been in the recent past to obtain approval to secure funding to protect systems against failure.
In many ways, the reluctance to provide funding for HA mirrors the problem in getting approval to implement better systems management tools generally. It is to be hoped that, as genuine HA systems become more affordable, organisations recognise the value of good management tools to help ensure higher levels of service delivery and the undoubted business benefits delivered by IT as a result.
