This article is more than 1 year old
The GPU tails wag the CPU dogs at Nvidia show
Where are the Tesla roadmaps?
One more interesting option
What I mean by this is very simple. Last November, tongues were a-wagging last November that Nvidia had hired some engineers from the defunct Transmeta, a maker of low-power clone x86 chips. A year earlier, there were rumors that Nvidia would buy clone x64 chip maker VIA Technologies.
Both rumors have been stepped on, and Nvidia has said it would stick with the GPU business and not get into the CPU business. But what about embedding an x64 processor in the GPU package? What would happen if you created a GPU that could run a Linux kernel and the same MPI-based applications and had a fast link on the chip package to the GPU and its memory? You could put a bunch of these PCI-Express ceepie-geepies inside of a barebones server that provides connectivity out to switches and disk/flash storage.
It's an interesting thought. But Gupta didn't want to talk about any of this, and instead wanted to focus on the success of the Nvidia Tesla 20 GPU co-processors and the uptake of the CUDA programming tools for these GPUs.
As best as Nvidia can figure, there are more than 1,000 HPC clusters configured with Tesla GPUs running out there in the world. There are some 100,000 active developers working on porting code to GPUs, says Gupta, and 350 universities worldwide are teaching CUDA as part of their computer science programs.
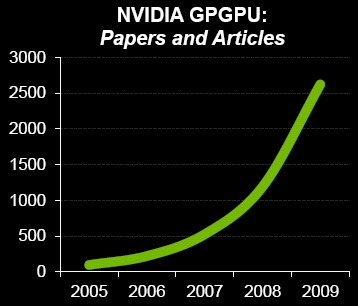
The Nvidia GPU paper chase
"I have been in the parallel computing business for a long time, and I have never seen a programming model take off like this," says Gupta. As part of the festivities at the GPU Tech Conference this week, the Portland Group, which makes C/C++ and Fortran compilers popularly used in the HPC community, will announce a CUDA for x86 compiler that can sense whether an Nvidia GPU is present or not and compile two sets of code - one for just CPUs and one for CPU-GPU hybrids and run whichever set of code makes sense given the underlying hardware. The CPU side of the compiler has optimizations to help it make better use the multiple threads and cores in modern x64 CPUs; it is not just tossing the code on the x64 chip and saying that this is good enough.
Different HPC communities are also getting behind GPUs, mostly because there is no other way to get cheap flops within a given thermal envelope. The NIMA weather model at the National Oceanographic and Atmosphere Administration is getting a ground-up redesign with GPUs in mind, and so is the Tsunami weather model supported by the Japanese government and the ocean circulation model maintained by the Massachusetts Institute of Technology. The National Institute for Environmental Studies in Japan has just installed a CPU-GPU cluster and is porting its carbon dioxide emissions model for the country to the hybrid setup.
Various life sciences, engineering, astrophysics, and mathematical applications are being ported to CUDA as well. The Amber molecular dynamics, Ansys finite element analysis, and MatLab mathematical programs were singled out for supporting CUDA and Tesla GPUs. The first two have hundreds of thousands of users worldwide, who have been trapped by the limitations of their workstations and multicore x64 processors just don't provide the kind of oomph they need.
On one test, the Amber program was ported using MPI to the "Kraken" Opteron-based massively parallel supercomputer installed at Oak Ridge National Laboratory, which has 99,072 cores and is rated at 1.03 petaflops. Running a molecular modeling benchmark called JAC NVE, the Kraken XT5 super was able to simulate 46 nanoseconds of the molecule per day of compute time running on a 192-core partition of the Kraken super, while a server with eight of the M2050 embedded GPUs for servers could do 52 nanoseconds of molecular simulation per day. It is not clear what would happen if you tried to run Kraken over all of its cores, but most of us don't have $45m or so it would take to build such a petaflops workstation.
Bootnote: Although Sumit Gupta, senior product manager of the Tesla line, told El Reg that Nvidia was not going to talk roadmaps, Dan Olds, our HPC compatriot, said that Jen-Hsun Huang, president and CEO at Nvidia, pulled rank and decided to give out some details on future GPUs. We'll let you know as soon as we find out the details. ®
