This article is more than 1 year old
Cray launches Gemini super interconnect
Last Baker system component revealed
The Gemini interconnect is half-way between the current SeaStar family of interconnects (SeaStar in the XT3, SeaStar2 in the XT4, and SeaStar2+ in the XT5) that the US government footed the bill for through various projects and a future hybrid computing system code-named "Cascades." The Cascades interconnect will support Xeon, Opteron, and other computing architectures, including Cray's MTA-2 processors, FPGAs (which Cray has shipped for years but which is not currently standard products as they were with the XT5 and earlier OctigaBay boxes), and very likely graphics co-processors.
Cray is being vague on the details behind Cascades. But what Bolding can say is that DARPA is paying for the research and development for Cascades and that one of the key elements of these systems is a brand new interconnect code-named "Aries", which will use PCI-Express links to lash processors to the interconnect rather than the HyperTransport links used with SeaStar and Gemini.
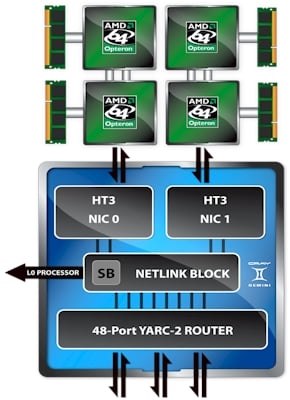
The architecture of the Cray Gemini interconnect
Why, you ask? Because Cray wants to be able to mix and match processors as it sees fit and not be screwed.
When the "Red Storm" Opteron-Linux massively parallel super was created for Sandia National Laboratories for delivery in late 2003, Intel's Xeon processors had the crappy frontside bus architecture and Opterons had that brand spanking new HyperTransport point-to-point interconnect. It took Intel until last year to get its equivalent of HyperTransport, called QuickPath Interconnect, to market in two-socket servers in the Xeon 5600s and only two months ago did larger server nodes (with more memory capacity) using the Xeon 7500s get QPI.
Opterons were the bomb in 2003, when they debuted, but Cray needs to keep its options open. So, says Bolding, the future Aries interconnect being put into Cascades systems will talk to PCI-Express instead of HT or QPI. (Which also seems to suggest that future Opteron and Xeon processors will have embedded PCI-Express circuits.)
But in the meantime, Cray needs to build and sell HPC iron today. So it took the high radix router that is being developed for DARPA under the Cascades contract and back-ported an early version of it to support HT3 links and the Opteron 6100 processors, thus creating the interconnect called Gemini. And so, Gemini is not getting its name from being two goosed SeaStar interconnects working side-by-side, as many have been speculating, including myself. It is a little more complex than that.
(By the way, DARPA is paying for the X64 portion of the Cascades system, and the initial machines will be based on Intel's Xeon processors. Bolding won't say whether Cray is or is not going to support Opterons with Cascades, but merely says Cray is "designing Cascades for flexibility" and that it "reserves the right to choose the best processor available at the time.")
The SeaStar interconnect took one HT link coming off a pair of Opteron processors and hooked it into a six-port router, with each port able to deliver 9.6 GB/sec of bandwidth. (The SeaStar is actually a bunch of chips, including the router, a blade control processor interface, a direct memory access engine, some memory, and the HT interface.) The HT2 links provided 25.6 GB/sec of bandwidth to memory on the two sockets of Opterons, 6.4 GB/sec of bandwidth from the processors out to the SeaStar2+ ASIC, and then six router ports running at 9.6 GB/sec each, implementing a 3D torus.
With Gemini, instead of one pair of Opteron chips linking into the Cray ASIC, there are two pairs and they link into the Gemini interconnect chip using HT3 links. And instead of having a dozen hard-coded pipes running at something north of 9.6 GB/sec, the Gemini chip has 48 skinnier ports that have an aggregate bandwidth of 168 GB/sec. Bolding says that four of these pipes, which are implemented using what is called a high radix YARC router with adaptive routing, can be used to make what amounts to a virtual network interface to talk to compute nodes.
The Gemini interconnect has one third or less the latency of the SeaStar2+ interconnect, taking just a hair above one microsecond to jump between computer nodes hooked to different Gemini chips, and less than one microsecond to jump from any of the four processors talking to the same Gemini. Perhaps more significantly, by ganging up many pipes using the high radix router, the Gemini chip can deliver about 100 times the message throughput of the SeaStar2+ interconnect - something on the order of 2 million packets per core per second, according to Bolding. (The amount will change depending on packet size and the protocol used, of course.)
That extra bandwidth means a lot more scalability. The Bakers, now formally known as the XE6 systems, will have at least four times the scalability of the current XT6 machines Cray is selling. "Because of this messaging rate, we think we can support a one million core system," says Bolding, which is about four times that of the current theoretical peak of the XT6/SeaStar2+ machines. And, Bolding adds, the theoretical scalability of the Baker machines is really on the order of around three million cores, assuming a 16-core "Interlagos" chip for next year. That's about 1,000 racks of server blades, which is about five times as many cabinets as in the 1.76 petaflops "Jaguar" massively parallel cluster running at Oak Ridge National Laboratory.
The XE6 is designed to scale from 100 teraflops up to multiple sustained petaflops, with a price tag starting at around $2m. There is not currently an XE6m midrange lineup, which will sport a 2D torus interconnect for smaller installations ranging from 10 teraflops to 100 or more teraflops, in a price range of $500,000 to $3m. But Bolding says there are plans to get an XE6m out the door eventually. Right now, the XT6m can do the job just fine.
Since the machines all implement the same 3D torus, you can swap out the SeaStar2+ interconnect on XT5 and XT6 machines and plug in the Gemini module and convert them into XE5 and XE6 machines. And, by choosing a 3D torus interconnect, that means the nodes in these upgrades systems do not have to be rewired, which is a requirement with many other supercomputer topologies.
In terms of power efficiency, the XT5 and XT5m machines delivered about 250 megaflops per watt, but the XT6 and XE6 machines will be 330 megaflops per watt or higher once they are put through the Linpack paces. Somewhere between 30 and 40 per cent improvement in energy efficiency is expected with the intial XT6 and XE6 boxes.
