This article is more than 1 year old
AMD cuts to the core with 'Bulldozer' Opterons
The future is modular
Performance times 1.8
As it turns out, this sharing of components across the cores impacts performance. Fruehe says that a pair of Bulldozer "cores" will yield about 1.8 times the performance of what a single, whole core would have. AMD will probably see a bunch of raised eyebrows about this 10 per cent performance hit at first. But Fruehe says that it is this modular approach to core design that will allow AMD to crank up to 16 cores into a single chip in 2011 with the "Interlagos" top-end Opterons, presumably to be called the Opteron 6200s, and stay in the same thermal bands as the current six-core "Istanbul" Opteron 8400 chips.
And maybe equally importantly, the modular approach provides standard interfaces into the Bulldozer crossbar, L3 cache, and northbridge that glues multiple Bulldozers together into an Interlagos (12 or 16-core for 2P and 4P servers) or a "Valencia" (6 or 8 cores for 1P and 2P servers) Bulldozer chip. These standard interfaces allow multiple Bulldozer modules to be plunked onto the die and linked together as a single multicore die.
Perhaps many years from now, this modularity and standard interfaces to the on-chip crossbar will allow graphic processing units (GPUs) and other application-specific units (APUs) to be etched onto the die of specific variants of Opterons. Network interfaces and PCI-Express controllers could also be scratched onto the dies as well, but Fruehe said you have to be careful with too much integration. A $5 serial port etched onto the die could get some gunk on it and destroy a $1,000 chip.
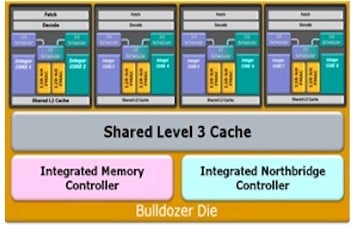
The logical layout of the Valencia Bulldozer Opteron
In the more immediate future, it would be interesting to see AMD take some partial Bulldozer chip duds that have one integer unit with a booger on it that makes it not work but which have their floating point units working fine and make special HPC version of the chip where each core can do eight flops per clock. This chip could also be run at a slightly higher clock speed, and with anywhere from six to eight cores, might yield a lot better bang for the buck on HPC workloads than a full-tilt 16-core Interlagos. (You can bet Cray customers using its XT family of parallel Opteron boxes would be interested in such a chip). This is just El Reg speculation, of course.
Instead of doing shared core modules, as it is doing with the Bulldozer designs, you might be thinking that AMD should have implemented simultaneous multithreading (SMT), as all other modern processors have done. Just to name two chips that have SMT: Sun Microsystems' Sparc T2 chips have eight cores, with eight integer threads per core and one floating point unit per core; IBM's Power7 chip will have eight cores, with each core having four threads for integer work, four double-precision FP units, a decimal math unit, and a vector math unit). Intel has, of course, implemented HyperThreading, its SMT variant, for years, when it was clear that AMD could get to multiple real cores way ahead of Intel.
Fruehe says that HyperThreading only gets customers a 10 to 20 per cent performance boost, and that there are, in fact, plenty of workloads where turning off HyperThreading lets workloads run faster. "We'd rather throw real cores at the problem," he says with a certain amount of disdain. "HyperThreading is a band-aid for a long pipeline and poor latency, and I have never seen a workload where throwing more cores at it didn't do better."
Better than HyperThreading, Fruehe meant to say. There are, of course, plenty of workloads where throwing more cores at them doesn't do anything to boost performance.
The initial Bulldozer processors will plug into the impending G34 and C32 sockets being used by the next generation of Opteron chips, due early next year. Both the Interlagos and Valencia Opterons will use a 32 nanometer high-metal gate processor. The Interlagos chips will come in standard speeds with the 75 watt power envelope, with slightly higher clock speeds coming with Special Edition (SE) parts that are rated at 105 watts and Highly Efficient (HE) low-voltage parts rated at 55 watts; the Interlagos parts will not have a 40-watt super-low-voltage Extremely Efficient (EE) variant.
The Valencia variants of the Bulldozer chips will come in standard, HE, and EE variants, but will not have SE parts. By chopping out the SE power requirements, AMD can make cheaper and more power-conserving Valencia parts, says Fruehe.
This is exactly the same distribution of Opteron parts we will see in the first quarter of next year with the high-end Opteron 6100s and the low-end Opteron 4100s.
Fruehe was not at liberty to say if the Bulldozer chips have taped out yet, but did confirm that the design is done and that Bulldozers would launch in 2011, "and not on December 31, either," he added with a laugh.
Where is that "Nehalem EX" eight-core monster from Intel again? ®
